dlPrune
Description
L'action (https://documentation.sas.com/doc/fr/pgmsascdc/v_073/casdlpg/cas-deeplearn-dlprune.htm) permet d'élaguer (pruner) une ou plusieurs couches d'un modèleReprésentation mathématique entraînée sur des données pour capturer des tendances, prédire des résultats ou classifier des observations via des algorithmes (Régression, Forêt aléatoire, Gradient Boosting). d'apprentissage profondL'apprentissage profond (Deep Learning) est une branche de l'IA utilisant des réseaux de neurones multicouches pour modéliser des données complexes et automatiser l'extraction de caractéristiques.. Ce procédé supprime les connexions dont l'impact est négligeable, ce qui allège considérablement les modèles obèses (un petit régime avant l'été pour vos réseaux de neurones !) tout en préservant globalement leurs performances.
Paramètres Clés
| Nom du paramètre | Description |
|---|---|
| bufferSize | Spécifie le nombre d'observations à conserver en mémoire avant de traiter le reste du mini-batch. |
| fitTolerance | Définit le seuil supérieur toléré pour l'erreur d'ajustement finale. |
| gpu | Active l'accélération matérielle GPU pour les calculs (vivement recommandé pour ne pas attendre la fin des temps). |
| includeFitStat | Si défini sur True, calcule et retourne les statistiques d'erreur et de perte après chaque opération d'élagage. |
| initWeights | La table en mémoire contenant les poids initiaux de votre modèle avant son régime. |
| layerNames | Une liste des noms des couches ciblées par l'élagage (celles qui vont être passées à la tronçonneuse). |
| maxIters | Le nombre maximum d'itérations permises pour l'élagage. |
| modelOut | Le nom de la table de sortie où sera conservé le nouveau modèle aminci. |
| modelTable | La table représentant l'architecture de votre modèle existant. |
| modelWeights | La table de sortie qui contiendra les nouveaux poids élagués. |
| pruneMetric | Détermine quelle métrique surveiller pendant l'élagage : `FITERROR` (erreur d'ajustement) ou `LOSS` (perte totale). |
| table | La table des données d'entrée utilisées pour évaluer la perte lors de l'élagage. |
Préparation des données
Chargement de la table d'évaluation
Chargement d'une table d'images et de labels (préalablement construite) pour évaluer l'impact de l'élagage sur les performances du modèle.
| 1 | PROC CAS; TABLE.loadTable / caslib="casuser" path="my_eval_data.sashdat" casout={name="my_eval_data", replace=true}; RUN; |
Exemples d'utilisation
Élagage basique d'une couche convolutive
Exemple rudimentaire ciblant une seule couche pour l'alléger en s'appuyant sur des poids préalablement entraînés.
| 1 | PROC CAS; DEEPLEARN.dlPrune / initWeights={name="model_weights"}, layerNames={"conv1"}, modelOut={name="pruned_model", replace=true}, modelTable={name="my_model"}, modelWeights={name="pruned_weights", replace=true}, TABLE={name="my_eval_data"}; RUN; |
Résultat Attendu :
Élagage avancé avec suivi et accélération GPU
On élague plusieurs couches avec une tolérance d'erreur spécifique, en activant l'accélération matérielle et le retour détaillé des métriques d'ajustement.
| 1 | PROC CAS; DEEPLEARN.dlPrune / fitTolerance=0.05, gpu={devices={0}, precision="FP32"}, includeFitStat=true, initWeights={name="model_weights"}, layerNames={"conv1", "fc1"}, maxIters=5, modelOut={name="pruned_model", replace=true}, modelTable={name="my_model"}, modelWeights={name="pruned_weights", replace=true}, pruneMetric="FITERROR", TABLE={name="my_eval_data"}; RUN; |
Résultat Attendu :
Sommaire
FAQ
 Quel est l'impact technique de l'accélération matérielle GPU sur la gestion de la mémoire tampon et des mini-lots ?
Quel est l'impact technique de l'accélération matérielle GPU sur la gestion de la mémoire tampon et des mini-lots ?
 Quels sont les leviers d'accélération GPU disponibles lors de la réduction des couches de réseaux de neurones ?
Quels sont les leviers d'accélération GPU disponibles lors de la réduction des couches de réseaux de neurones ?
 Quelle est l'architecture exacte des tables en mémoire requise pour exécuter un élagage réseau ?
Quelle est l'architecture exacte des tables en mémoire requise pour exécuter un élagage réseau ?
 Comment garantir la qualité et la stabilité du modèle prédictif après la suppression d'une couche critique ?
Comment garantir la qualité et la stabilité du modèle prédictif après la suppression d'une couche critique ?
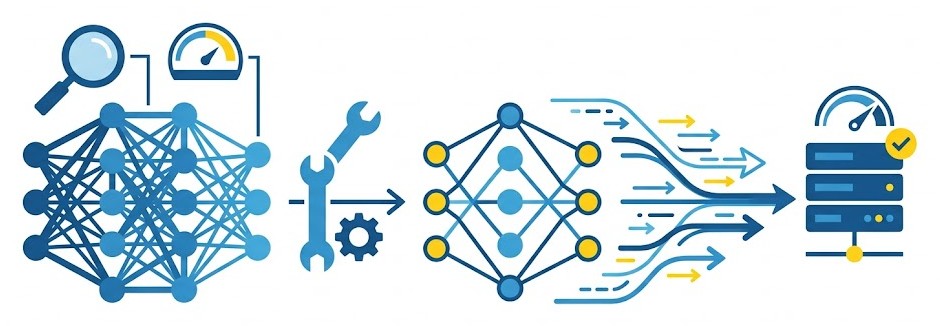 Comment l'action dlPrune optimise-t-elle l'inférence des modèles Deep Learning en production ?
Comment l'action dlPrune optimise-t-elle l'inférence des modèles Deep Learning en production ?