
Surveillance de SAS Viya sur Kubernetes

Avec SAS Viya, la plateforme analytique SAS prend un coup de jeune ! Conçue nativement pour le cloud et les environnements conteneurisés, elle a franchi une étape majeure. Depuis la version 2020.1 (ou SAS Viya 4), fini les installations classiques : tout est déployé via des conteneurs orchestrés par Kubernetes. Cette architecture moderne s'appuie sur Kubernetes pour gérer l'organisation, la mise à l'échelle et l'administration des applications avec agilité. La nature dynamique et distribuée d'un environnement Kubernetes rend les approches de surveillance traditionnelles, basées sur des fichiers journaux statiques, obsolètes. Les applications, serveurs et services SAS Viya s'exécutent désormais dans des pods Kubernetes éphémères, dont les journaux sont diffusés vers la sortie standard (stdout/stderr) au niveau du cluster. Par conséquent, une stratégie de surveillance et d'observabilité robuste, adaptée aux environnements cloud-natifs, est essentielle pour garantir la santé, la performance et la fiabilité des déploiements SAS Viya sur Kubernetes.
La nature dynamique et distribuée d'un environnement Kubernetes rend les approches de surveillance traditionnelles, basées sur des fichiers journaux statiques, obsolètes
Documentation Officielle et Ressources SAS
Pour naviguer dans la complexité de SAS Viya et de sa surveillance sur Kubernetes, il est crucial de s'appuyer sur la documentation officielle et les ressources fournies par SAS.
Pour la surveillance spécifiquement, la documentation relative à SAS Viya Monitoring for Kubernetes est primordiale. Cette documentation est accessible via le SAS Help Center et directement sur le référentiel GitHub du projet (sassoftware/viya4-monitoring-kubernetes). Ces ressources couvrent les prérequis, le déploiement, la personnalisation, l'utilisation des outils (Prometheus, Grafana, OpenSearch) et le dépannage de la solution de surveillance.
- About SAS Viya Monitoring for Kubernetes
- Welcome to SAS Viya Monitoring for Kubernetes
- Why Use SAS Viya Monitoring for Kubernetes?
Outils et Méthodes de Surveillance Recommandés
La surveillance d'un environnement SAS Viya sur Kubernetes implique l'utilisation d'une combinaison d'outils pour collecter, agréger et visualiser les logs, les métriques et potentiellement les traces. SAS propose une solution dédiée, mais d'autres outils peuvent également être utilisés.
SAS Viya Monitoring for Kubernetes (V4M)
C'est la solution de surveillance et d'observabilité recommandée et supportée par SAS pour Viya sur Kubernetes. Elle est basée sur des outils open-source reconnus et est disponible gratuitement sur GitHub. V4M fournit des scripts et des configurations pour simplifier le déploiement d'une pile d'observabilité complète.
- Composants Clés :
- Logging : Utilise Fluent Bit pour la collecte et la standardisation des logs de tous les pods du cluster, OpenSearch pour le stockage et l'indexation, et OpenSearch Dashboards (anciennement Kibana) pour la visualisation et l'analyse des logs. Une alternative utilisant Azure Monitor est également mentionnée.
- Métriques : Utilise Prometheus pour la découverte, la collecte et le stockage des métriques, et Grafana pour la visualisation via des tableaux de bord. Il inclut également Alertmanager pour la gestion des alertes basées sur les métriques et divers exporters (node-exporter, kube-state-metrics, exporters pour OpenSearch, PostgreSQL, RabbitMQ) pour exposer les métriques de différents composants.
- Avantages : Solution intégrée et supportée par SAS, spécifiquement conçue pour Viya, simplifie le déploiement d'outils open-source standards, fournit des tableaux de bord et configurations pré-paramétrés pour Viya.
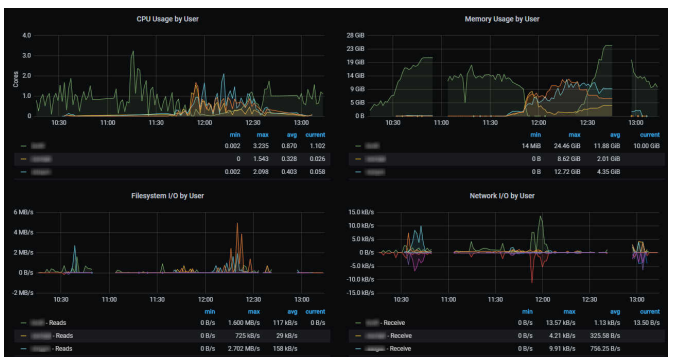
SAS Enterprise Session Monitor (ESM)
SAS ESM est un autre outil SAS qui peut être utilisé pour la surveillance, bien qu'avec un focus différent de V4M.
- Fonctionnalités : ESM est particulièrement fort pour fournir une visibilité détaillée sur les sessions utilisateur (SAS Programming et CAS), leur consommation de ressources, et le suivi des workflows utilisateur. Il peut observer différents types de déploiements SAS (SAS 9.4, Viya 3.x, Viya Platform) depuis un serveur ESM unique. Sur Kubernetes, il se concentre sur les composants Viya. Il collecte des métriques et des événements en analysant les logs des composants SAS.
- Comparaison avec V4M :
- Focus : ESM est orienté "métier" et analyse de sessions, tandis que V4M est orienté "IT" et surveillance de l'infrastructure Kubernetes et des applications.
- Portée : V4M offre une vue plus complète du cluster Kubernetes (tous les pods, événements K8s), tandis qu'ESM sur K8s se limite aux composants Viya.
- Stockage/Rétention : ESM utilise une base PostgreSQL avec une gestion flexible de la rétention via son interface. V4M utilise Prometheus (métriques) et OpenSearch (logs) avec une rétention configurée au déploiement.
- Complémentarité : Les deux outils peuvent être complémentaires. V4M fournit la surveillance de l'infrastructure et des logs/métriques de base, tandis qu'ESM offre une analyse approfondie des sessions spécifiques.
SAS ESM est un autre outil SAS qui peut être utilisé pour la surveillance, bien qu'avec un focus différent de V4M.
Outils Natifs Kubernetes et Autres
kubectl: L'interface de ligne de commande Kubernetes est un outil essentiel pour les diagnostics de base : vérifier l'état des pods (get pods,describe pod), consulter les logs en temps réel (logs), examiner les événements du cluster (get events), et obtenir une vue rapide de l'utilisation des ressources (top pod/node). Cependant,kubectlne fournit pas une vue agrégée ou historique, le rendant insuffisant pour une surveillance complète.- Kubernetes Dashboard : Une interface utilisateur web générale pour les clusters Kubernetes, qui peut offrir une vue d'ensemble de l'état du cluster et des applications.
- Solutions Cloud Natives : Si Viya est déployé sur un service Kubernetes géré (AKS, EKS, GKE), les outils de surveillance natifs du fournisseur cloud (Azure Monitor, AWS CloudWatch, Google Cloud Monitoring/Logging) peuvent être utilisés pour collecter logs et métriques. V4M inclut d'ailleurs des exemples et guides pour l'intégration avec ces suites.
- Autres Outils Open Source : Étant donné que SAS Viya est conçu selon les standards cloud-natifs, d'autres solutions de surveillance compatibles avec Kubernetes pourraient théoriquement être utilisées, bien que V4M soit la solution spécifiquement testée et supportée par SAS.
En résumé, SAS Viya Monitoring for Kubernetes (V4M) est la solution privilégiée, offrant une pile d'observabilité complète et intégrée basée sur Prometheus, Grafana et OpenSearch. SAS ESM peut la compléter pour une analyse détaillée des sessions. Les outils natifs Kubernetes comme kubectl restent indispensables pour les diagnostics directs.
Métriques Clés à Surveiller
Une surveillance efficace de SAS Viya sur Kubernetes nécessite de suivre un ensemble de métriques clés couvrant l'infrastructure sous-jacente, les applications SAS elles-mêmes, l'état des objets Kubernetes et les services de support.
Utilisation des Ressources de l'Infrastructure Kubernetes
Il est fondamental de surveiller la consommation des ressources au niveau des nœuds et des pods du cluster pour s'assurer que l'environnement dispose d'une capacité suffisante et pour identifier les goulots d'étranglement potentiels.
- CPU : Surveiller l'utilisation du CPU (%) au niveau du nœud, du pod et du conteneur. Il est crucial de distinguer l'utilisation réelle des requêtes et des limites configurées pour les pods. Comme mentionné précédemment, l'ordonnanceur Kubernetes se base sur les requêtes pour placer les pods. Une requête trop élevée peut empêcher un pod de démarrer même si le nœud a du CPU disponible en utilisation réelle.
- Mémoire : Suivre l'utilisation de la mémoire (par exemple, Working Set Size - WSS, RSS) au niveau du nœud, du pod et du conteneur. Là encore, la comparaison avec les requêtes et limites de mémoire est essentielle pour comprendre la pression sur les ressources et éviter les arrêts de pods dus à des dépassements de limites (OOMKilled). Une suggestion d'utiliser les valeurs WSS pour le pourcentage d'utilisation mémoire par rapport à la limite a été faite.
- Disque I/O et Espace : Surveiller les performances des entrées/sorties disque et l'espace disque disponible sur les nœuds, en particulier pour les volumes persistants (PVs) utilisés par les composants stateful comme OpenSearch ou Prometheus. Le suivi de l'utilisation des Persistent Volume Claims (PVCs) est également important.
- Réseau I/O : Suivre le trafic réseau (octets envoyés/reçus) à différents niveaux (cluster, namespace, pod) pour détecter les problèmes de saturation ou de communication.
- Outils : Ces métriques sont principalement collectées via Prometheus, qui utilise des agents comme
node-exporter(pour les métriques de nœud OS/matériel) etkube-state-metrics(pour l'état des objets K8s), puis visualisées dans Grafana via divers tableaux de bord dédiés à l'infrastructure Kubernetes.
Métriques Spécifiques aux Applications (Services SAS Viya)
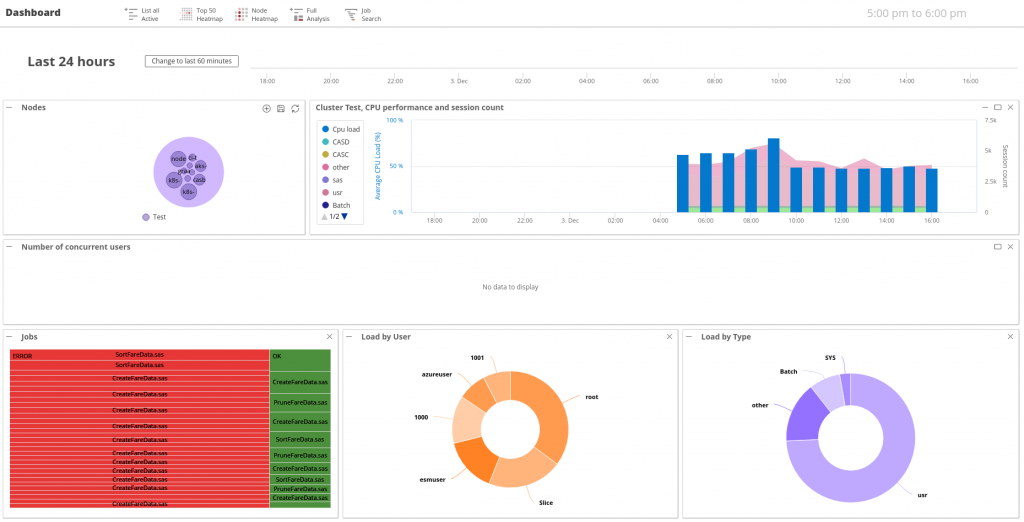
Au-delà de l'infrastructure, il faut surveiller la performance et la santé des composants SAS Viya eux-mêmes. (Grafana Dashboards Descriptions)
- Performance des Services SAS : Métriques spécifiques aux microservices SAS (souvent catégorisés comme services Go ou Java), incluant les temps de réponse, le débit de requêtes, les taux d'erreur, et l'utilisation des ressources par service.
- SAS Cloud Analytic Services (CAS) : Surveiller l'utilisation CPU et mémoire des serveurs CAS, potentiellement le nombre de sessions actives, l'état des workers, et peut-être la performance de certaines actions CAS critiques.
- SAS Compute Server : Suivre le nombre de sessions, l'utilisation des ressources par session ou par utilisateur (ESM est particulièrement adapté pour cela ), et potentiellement les temps d'exécution ou l'état des jobs soumis. Les événements d'accès aux jeux de données peuvent être capturés via la configuration de logs d'audit spécifiques.
- Outils : Les services Viya exposent leurs métriques via des points de terminaison (endpoints) Prometheus standard (HTTP/HTTPS). Prometheus collecte ces métriques (via la configuration mise en place par V4M), et Grafana les visualise à l'aide de tableaux de bord fournis par SAS. ESM fournit des métriques de session très détaillées.
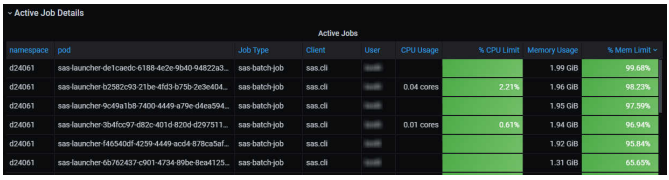
État des Objets Kubernetes
La santé globale de l'application dépend de l'état des objets Kubernetes qui la composent.
- État des Pods : Surveiller les phases des pods (Pending, Running, Succeeded, Failed, Unknown), le nombre de redémarrages (restarts), et l'état des sondes de préparation (readiness) et de vivacité (liveness). Un nombre élevé de redémarrages ou des pods non prêts indiquent des problèmes. L'état "Pending" peut bloquer le démarrage de services essentiels.
- État des Nœuds : Surveiller les conditions des nœuds (Ready, NotReady) et la pression sur les ressources (MemoryPressure, DiskPressure).
- État des Deployments/StatefulSets : Suivre le nombre de réplicas souhaités par rapport au nombre de réplicas actuels et disponibles, ainsi que la progression des mises à jour.
- Outils : Collecté via
kube-state-metricset visualisé dans Grafana. La commandekubectl describefournit des détails et les événements associés à un objet spécifique.
Métriques de l'Infrastructure de Support
SAS Viya dépend de plusieurs composants d'infrastructure critiques dont la santé doit également être surveillée.
- SAS Infrastructure Data Server (PostgreSQL) : Métriques de performance et d'utilisation de la base de données PostgreSQL (souvent la distribution Crunchy Data fournie avec Viya), telles que le nombre de connexions, l'utilisation du CPU/mémoire, le taux de transactions, l'utilisation de l'espace disque. V4M inclut un exporter et des tableaux de bord pour PostgreSQL/Crunchy Data.
- RabbitMQ : Métriques de performance et d'état des files d'attente pour le broker de messages utilisé par Viya (taux de messages, nombre de messages en attente, utilisation mémoire/CPU). V4M fournit des tableaux de bord pour RabbitMQ.
- Contrôleur d'Ingress : Surveiller les taux de requêtes, la latence, les codes d'erreur pour le composant gérant le trafic externe entrant vers Viya (par exemple, NGINX Ingress).
- Composants de Surveillance : Il est également sage de surveiller la santé et la performance des outils de surveillance eux-mêmes (Prometheus, Grafana, OpenSearch, Fluent Bit) pour s'assurer qu'ils fonctionnent correctement.
- Outils : Collecté via des exporters spécifiques (Postgres, RabbitMQ, OpenSearch) ou par Prometheus lui-même, et visualisé dans Grafana.
Tableau Récapitulatif des Catégories de Métriques Clés

Le tableau suivant résume les catégories de métriques essentielles et fournit des exemples concrets. L'utilisateur a besoin de savoir quoi surveiller, et ce tableau fournit des exemples concrets de métriques critiques à travers différentes couches du système, répondant directement au point 4 de la requête. Il agrège les types de métriques mentionnés dans divers extraits () en catégories logiques pour plus de clarté.
| Catégorie | Exemples de Métriques | Outil Principal |
|---|---|---|
| Utilisation des Ressources K8s | Utilisation CPU (%), Utilisation Mémoire (WSS), Requêtes/Limites CPU/Mémoire, I/O Disque/Réseau, Utilisation PVC | Prometheus / Grafana |
| Performance Applicative SAS | Taux d'erreur service, Latence service, Charge CPU CAS, Mémoire CAS, Sessions Compute actives, Accès aux datasets (Audit) | Prometheus / Grafana / ESM |
| État des Objets Kubernetes | Phase des Pods, Redémarrages Pods, État Nœud (Ready/NotReady), Réplicas Deployment/StatefulSet | Prometheus / Grafana / kubectl |
| Infrastructure de Support | Connexions PG Cluster, Transactions PG, Messages RabbitMQ en attente, Débit logs Fluent Bit, Santé OpenSearch | Prometheus / Grafana / OpenSearch Dashboards |
Une surveillance efficace nécessite une approche multicouche, observant non seulement les applications SAS elles-mêmes mais aussi la plateforme Kubernetes sous-jacente et les services de support (base de données, messagerie). Une défaillance ou un goulot d'étranglement dans n'importe quelle couche peut impacter la performance et la disponibilité globales de Viya.
Il est crucial de comprendre la distinction entre les requêtes de ressources Kubernetes et l'utilisation réelle. Les décisions d'ordonnancement de Kubernetes sont basées sur les requêtes déclarées par les pods, et non sur leur consommation instantanée. Cela signifie qu'une surévaluation significative des requêtes peut entraîner des échecs d'ordonnancement et un gaspillage de ressources, même si l'utilisation réelle est faible. Par conséquent, définir des requêtes et limites de ressources appropriées pour les pods Viya est essentiel et nécessite un ajustement basé sur les habitudes d'utilisation observées pour garantir à la fois la stabilité et l'utilisation efficace des ressources. Les outils de surveillance comme Grafana devraient être configurés pour visualiser à la fois l'utilisation et les requêtes/limites.
Configuration et Intégration des Outils de Surveillance
La mise en place et la configuration des outils de surveillance, en particulier SAS Viya Monitoring for Kubernetes (V4M), nécessitent une compréhension des mécanismes de déploiement et de personnalisation de Kubernetes.
Déploiement des Composants V4M
Le processus général de déploiement de V4M suit plusieurs étapes clés :
- Vérification des Prérequis : S'assurer que le cluster Kubernetes et l'environnement client répondent aux exigences système de V4M.
- Obtention des Fichiers V4M : Créer une copie locale du référentiel GitHub
viya4-monitoring-kubernetespour une version spécifique (généralement la dernière stable). - Préparation des Personnalisations : Examiner et préparer les fichiers de personnalisation nécessaires (variables d'environnement, patches YAML) en fonction des besoins spécifiques du déploiement (sécurité, rétention, etc.). Un répertoire utilisateur (
USER_DIR) est souvent utilisé pour stocker ces personnalisations. - Exécution des Scripts de Déploiement :
- Utiliser
logging/bin/deploy_logging.sh(ou une variante spécifique à l'OS/environnement comme OpenShift) pour déployer les composants de logging (Fluent Bit, OpenSearch, OpenSearch Dashboards). Ce script crée généralement un namespace dédié (par défautlogging), sauf dans certains cas comme les déploiements air-gapped. - Utiliser
monitoring/bin/deploy_monitoring_cluster.shpour déployer les composants principaux de métriques (Prometheus Operator, Prometheus, Alertmanager, Grafana, exporters de base). Ce script crée aussi typiquement un namespace dédié (par défautmonitoring).
- Utiliser
- Activation de la Surveillance Viya : Une fois V4M et la plateforme SAS Viya déployés, exécuter
VIYA_NS=<Viya_namespace> monitoring/bin/deploy_monitoring_viya.shen spécifiant le namespace où Viya est déployé. Cette étape est cruciale car elle déploie les configurations (ServiceMonitors/PodMonitors) qui indiquent à Prometheus comment découvrir et collecter les métriques spécifiques aux services Viya. Sans cette étape, seules les métriques Kubernetes génériques seront visibles.
Personnalisation de V4M
V4M offre plusieurs mécanismes pour adapter le déploiement aux besoins spécifiques :
- Variables d'Environnement : De nombreuses configurations peuvent être définies via des variables d'environnement, soit exportées dans le shell, passées en ligne de commande lors de l'exécution des scripts, ou définies dans un fichier
user.envsitué dans le répertoire de personnalisation (USER_DIR). Exemples :GRAFANA_ADMIN_PASSWORD,LOG_RETENTION_PERIOD. - Fichiers de Personnalisation YAML : Des patches Kustomize ou des fichiers YAML spécifiques peuvent être placés dans des sous-répertoires dédiés (par exemple, sous
USER_DIRousite-configsi utilisé avec Ansible ) pour modifier plus en profondeur la configuration des composants. - Fichiers
user-values-*.yaml: Pour les composants déployés via Helm (comme Prometheus Operator et ses dépendances), des fichiersuser-values-*.yamlpeuvent être créés dans le répertoire de personnalisation pour surcharger les valeurs par défaut du chart Helm. C'est la méthode utilisée, par exemple, pour configurer un registre privé dans un déploiement air-gapped. - Exemples de Personnalisation : Définition des mots de passe administrateur pour Grafana et OpenSearch , configuration des périodes de rétention des logs et métriques , configuration de TLS , personnalisation du placement des workloads sur les nœuds , configuration pour OpenShift , configuration pour environnements air-gapped.
Intégration Prometheus (ServiceMonitors/PodMonitors)
L'intégration entre Prometheus et les services SAS Viya repose sur le Prometheus Operator, un composant clé de V4M.
- Principe : Le Prometheus Operator utilise des Custom Resource Definitions (CRDs) Kubernetes appelées
ServiceMonitoretPodMonitor. Ces ressources décrivent comment Prometheus doit découvrir les points de terminaison de métriques exposés par les services Kubernetes (viaServiceMonitor) ou directement par les pods (viaPodMonitor) et comment collecter (scraper) les métriques depuis ces points de terminaison. - Rôle de
deploy_monitoring_viya.sh: Ce script (mentionné en V.A.5) est responsable de la création desServiceMonitorset/ouPodMonitorsnécessaires dans le namespace Viya cible. Ces moniteurs sont spécifiquement configurés pour les services SAS Viya (CAS, microservices Go/Java, etc.) qui exposent des métriques au format Prometheus. - Découverte Automatique : Le Prometheus Operator surveille la création/modification/suppression de ces ressources
ServiceMonitoretPodMonitoret met automatiquement à jour la configuration de scraping de l'instance Prometheus déployée, assurant ainsi que les métriques Viya sont collectées.
Configuration de Grafana
Grafana est l'outil de visualisation des métriques dans V4M.
- Tableaux de Bord (Dashboards) : V4M inclut un grand nombre de tableaux de bord pré-construits pour visualiser les métriques Kubernetes et SAS Viya. Le tableau de bord "SAS Viya Welcome" sert de point d'entrée et de guide. Les tableaux de bord sont souvent organisés par tags (par exemple,
sas-viya,kubernetes) pour faciliter la navigation. - Accès et Permissions : Par défaut, l'utilisateur
admin(dont le mot de passe peut être défini au déploiement ) a accès à tous les tableaux de bord. Grafana permet de configurer des permissions plus fines pour restreindre l'accès des autres utilisateurs à certains tableaux de bord ou dossiers. L'intégration avec des annuaires d'entreprise comme LDAP/AD est une fonctionnalité demandée par la communauté. - Alertes : Grafana dispose de fonctionnalités d'alerte permettant de déclencher des notifications basées sur des requêtes PromQL (le langage de requête de Prometheus). La configuration implique de définir des "Contact points" (canaux de notification, par exemple email via SMTP configuré dans Grafana ) et des "Alert rules" qui spécifient les conditions de déclenchement. Prometheus Alertmanager, également inclus dans V4M, est une autre option robuste pour gérer le routage et la déduplication des alertes générées par Prometheus. L'authentification pour Prometheus et Alertmanager est également une fonctionnalité souhaitée.
- Intégration avec SAS Environment Manager : Il est possible de configurer des liens directs vers les tableaux de bord Grafana (et OpenSearch Dashboards) depuis l'interface de SAS Environment Manager pour un accès facilité aux administrateurs SAS.
Configuration d'OpenSearch/Dashboards
OpenSearch et son interface OpenSearch Dashboards gèrent l'agrégation et la visualisation des logs.
- Rétention des Logs : La durée de conservation des logs est gérée par des politiques de gestion d'index (Index State Management - ISM) dans OpenSearch. V4M définit des politiques par défaut (par exemple,
viya_logs_idxmgmt_policy) avec des durées de rétention potentiellement courtes (ex: 3 jours pour les logs Viya, 1 jour pour les logs de monitoring). Cette durée peut être ajustée avant le déploiement via des variables d'environnement (ex:LOG_RETENTION_PERIOD) ou modifiée après le déploiement via l'API OpenSearch ou l'interface Dashboards. Modifier la rétention après un premier déploiement peut nécessiter des étapes spécifiques, potentiellement une recréation du namespace de logging si la modification est faite via les variables d'environnement pré-déploiement. - Utilisateurs et Accès : Des utilisateurs par défaut comme
adminetlogadm(pour l'administration quotidienne) sont créés. Leurs mots de passe peuvent être définis avant le déploiement. OpenSearch Dashboards supporte les "espaces" (spaces) pour une forme de multi-tenanting ou de séparation logique des vues. L'intégration LDAP est une amélioration demandée.
Intégration de SAS ESM
Si SAS ESM est utilisé conjointement ou à la place de V4M pour certains aspects :
- Configuration de l'Agent : Le déploiement des agents ESM est nécessaire. Des configurations spécifiques peuvent être requises dans SAS Viya via SAS Environment Manager pour activer la collecte de certaines métriques, comme l'audit d'accès aux datasets (logger
Audit.Data.Dataset), ce qui nécessite au préalable de positionner la variableSAS_ALLOW_ADMIN_SCRIPTSàtruedans la configuration partagée de Viya. - Gestion des Certificats : Si TLS est utilisé pour sécuriser la communication entre Viya et ESM, le certificat d'ingress de Viya doit être extrait et appliqué à la configuration du serveur/namespace ESM.
La configuration de la surveillance est gérée par une combinaison de variables d'environnement, de patches Kustomize/YAML et de valeurs Helm, ce qui requiert une familiarité avec ces paradigmes de configuration Kubernetes. Ces mécanismes sont les standards pour adapter le déploiement de la surveillance.
L'intégration de la pile de surveillance (V4M) avec le déploiement SAS Viya cible est une étape distincte (deploy_monitoring_viya.sh) qui active la collecte des métriques spécifiques à Viya via les ServiceMonitors/PodMonitors du Prometheus Operator. Cette étape est indispensable pour obtenir des données Viya dans Prometheus.
Les configurations par défaut fournies par V4M, en particulier pour la rétention des données, peuvent nécessiter des ajustements pour les environnements de production en fonction de la capacité de stockage et des exigences de conformité. Les durées de rétention par défaut sont souvent courtes et doivent être activement revues et modifiées. Une gestion rigoureuse de la configuration (par exemple, en utilisant Git pour les fichiers de personnalisation comme recommandé ) est cruciale pour assurer des déploiements de surveillance reproductibles et maintenables. Les changements, en particulier ceux affectant la rétention ou les paramètres fondamentaux, doivent être planifiés avec soin.
Meilleures Pratiques pour la Surveillance et l'Observabilité
Adopter des meilleures pratiques est essentiel pour maximiser l'efficacité et la fiabilité de la surveillance de SAS Viya sur Kubernetes.
Adopter les Piliers de l'Observabilité
Utiliser V4M (ou les outils choisis) pour collecter et corréler les Logs, les Métriques, et (si pertinent et disponible) les Traces afin d'obtenir une vue holistique du système. Il faut noter que le support du traçage dans V4M et Viya est actuellement considéré comme expérimental. L'objectif est de pouvoir passer facilement d'une métrique anormale aux logs correspondants ou à une trace d'exécution pour un diagnostic rapide.
Pratiques de Sécurité
La sécurité de la pile de surveillance elle-même est primordiale car elle collecte des données opérationnelles potentiellement sensibles.
- Gestion de la Configuration : Utiliser un système de contrôle de version (comme Git) pour tous les fichiers de personnalisation de V4M (
user.env, patches YAML,user-values-*.yaml). Cela assure la traçabilité, la reproductibilité et facilite la collaboration sécurisée. - Contrôle d'Accès : Limiter strictement l'accès aux fichiers de déploiement/configuration et aux namespaces Kubernetes dédiés à la surveillance (
logging,monitoring) aux seules personnes autorisées (par exemple, les ingénieurs de déploiement). - Gestion des Secrets : Ne jamais stocker de mots de passe en clair dans les fichiers de configuration. Utiliser des variables d'environnement injectées via des secrets Kubernetes, ou des outils de gestion de secrets dédiés. Définir les mots de passe requis (Grafana admin, OpenSearch users) lors du déploiement via les mécanismes prévus.
- Nettoyage Post-Déploiement : Si un hôte bastion (jump host) est utilisé pour le déploiement, supprimer tous les artefacts de déploiement (fichiers de configuration contenant potentiellement des secrets, scripts) de cette machine une fois le déploiement réussi.
- Sécurisation des Communications : Configurer TLS pour sécuriser l'accès aux interfaces web (Grafana, OpenSearch Dashboards) et potentiellement pour la communication interne entre les composants de surveillance, si nécessaire.
Maintien à Jour des Logiciels
Les logiciels évoluent, incluant des correctifs de sécurité et de nouvelles fonctionnalités.
- SAS Viya : Maintenir la plateforme SAS Viya à jour en suivant la cadence choisie (Stable mensuelle ou Long-Term Support semestrielle). Appliquer les patchs dès qu'ils sont disponibles.
- SAS Viya Monitoring for Kubernetes : Mettre à jour V4M vers la dernière version disponible sur GitHub régulièrement (SAS recommande au moins tous les six mois). Cela permet de bénéficier des derniers correctifs, mises à jour de sécurité des composants open-source inclus, et améliorations fonctionnelles. La mise à jour de V4M est un processus distinct de la mise à jour de Viya.
Gestion de la Rétention des Données et du Stockage
La surveillance génère un volume important de données qui doit être géré.
- Planification de la Rétention : Définir et configurer des périodes de rétention appropriées pour les logs dans OpenSearch et les métriques dans Prometheus. Ces durées doivent être basées sur les besoins opérationnels (combien de temps faut-il pour investiguer un incident?), les exigences de conformité, et la capacité de stockage disponible. Les valeurs par défaut sont souvent trop courtes pour une production.
- Surveillance du Stockage : Surveiller activement la consommation d'espace disque par les volumes persistants (PVCs) utilisés par Prometheus et OpenSearch. Être conscient des limitations potentielles des systèmes de fichiers réseau (NFS) qui pourraient ne pas appliquer strictement les quotas de PVC. Utiliser les mécanismes de rétention intégrés aux outils (taille maximale pour Prometheus , politiques ISM pour OpenSearch ) pour contrôler la croissance des données.
Allocation des Ressources
Les composants de surveillance consomment eux-mêmes des ressources.
- Dimensionnement : Allouer suffisamment de ressources (CPU, mémoire, stockage) aux pods de la pile de surveillance (Prometheus, Grafana, OpenSearch, Fluent Bit, etc.) pour qu'ils puissent fonctionner efficacement, même en cas de charge élevée sur le cluster Viya.
- Surveillance des Outils : Utiliser les outils de surveillance pour surveiller leur propre consommation de ressources.
- Priorisation (Optionnel) : Envisager de configurer des priorités ou des garanties de qualité de service (QoS) pour les pods de surveillance critiques afin d'éviter qu'ils ne soient arrêtés (évincés) en cas de forte pression sur les ressources d'un nœud.
Exploitation des Alertes et Tableaux de Bord
La collecte de données n'est utile que si elle est exploitée.
- Alertes Pertinentes : Configurer des alertes significatives pour les conditions critiques : saturation des ressources (CPU, mémoire, disque), indisponibilité de services clés (CAS, services Viya critiques, base de données), taux d'erreur élevés, files d'attente RabbitMQ pleines, etc. Utiliser Prometheus Alertmanager ou les alertes Grafana. Affiner les seuils pour éviter le bruit excessif (fausses alertes).
- Visualisation Efficace : Utiliser les tableaux de bord Grafana fournis par V4M comme point de départ. Personnaliser les tableaux de bord existants ou en créer de nouveaux pour visualiser les indicateurs de performance clés (KPIs) spécifiques à l'environnement et aux objectifs métier. Adopter une approche "du général au particulier" : commencer par des vues d'ensemble (cluster, namespace) puis explorer les détails en cas d'anomalie.
- Optimisation des Requêtes : Utiliser les "recording rules" de Prometheus pour pré-calculer des métriques agrégées ou des requêtes coûteuses qui sont fréquemment utilisées dans les tableaux de bord ou les alertes, afin d'améliorer les performances.
Stratégie de Sauvegarde (Contexte)
Bien que n'étant pas une pratique de surveillance directe, une stratégie de sauvegarde robuste pour l'environnement SAS Viya lui-même est un complément essentiel. Avant toute mise à jour logicielle majeure (Viya ou V4M) ou changement de configuration significatif, s'assurer qu'une sauvegarde récente et valide de Viya a été effectuée. Les données de surveillance peuvent aider à diagnostiquer les problèmes post-mise à jour, mais une sauvegarde est nécessaire pour une éventuelle restauration. Les sauvegardes sont spécifiques à une version et une cadence données.
La surveillance de SAS Viya sur Kubernetes est un processus continu qui exige une discipline opérationnelle. Elle nécessite des mises à jour régulières de la pile de surveillance elle-même, une vigilance constante en matière de sécurité, et un ajustement continu des configurations (rétention, ressources, alertes).
La sécurité est un aspect fondamental, car la pile de surveillance centralise des informations opérationnelles critiques. Les pratiques de base comme le contrôle d'accès, la gestion des secrets et la sécurisation des communications doivent être appliquées rigoureusement.
Les configurations par défaut fournies par V4M, notamment en ce qui concerne la rétention des données, doivent être considérées comme des points de départ. Chaque organisation doit activement évaluer et ajuster ces paramètres en fonction de ses propres contraintes et exigences. Cela implique d'allouer des ressources continues et d'établir des processus clairs pour la maintenance de l'infrastructure de surveillance.
Dépannage des Problèmes Courants de Surveillance
Même avec une configuration soignée, des problèmes peuvent survenir. Savoir comment les diagnostiquer est crucial.
Outils de Diagnostic
kubectl: Reste l'outil de première ligne pour interagir avec le cluster Kubernetes.kubectl get pods -n <namespace>: Vérifier l'état (Status) et le nombre de redémarrages (Restarts) des pods Viya ou de surveillance.kubectl describe pod <pod-name> -n <namespace>: Obtenir des informations détaillées sur un pod, y compris les événements récents qui expliquent souvent pourquoi un pod est en état Pending, CrashLoopBackOff, ou ne passe pas les sondes de santé.kubectl logs <pod-name> [-c <container-name>] -n <namespace>: Consulter les logs en temps réel ou passés d'un conteneur spécifique dans un pod. Utile si OpenSearch n'est pas accessible ou si le problème concerne un pod de la pile de surveillance elle-même.kubectl top pod/node [-n <namespace>]: Afficher l'utilisation actuelle du CPU et de la mémoire par les pods ou les nœuds.kubectl get events -n <namespace>: Lister les événements récents dans un namespace, pouvant révéler des problèmes de planification, de tirage d'image, etc..
- Outils V4M :
- OpenSearch Dashboards : Utiliser l'interface pour rechercher, filtrer et analyser les logs agrégés de l'ensemble du cluster ou de services spécifiques. Rechercher des messages d'erreur ou des motifs inhabituels.
- Grafana : Examiner les tableaux de bord pour identifier des anomalies dans les métriques (pics de CPU/mémoire, latence élevée, taux d'erreur), vérifier la disponibilité des services.
- Prometheus UI : Accessible généralement via un port-forward ou une ingress dédiée, l'interface web de Prometheus permet de vérifier l'état des cibles de scraping (Targets -> si des services Viya sont marqués comme "Down"), d'exécuter des requêtes PromQL ad-hoc, et de vérifier la configuration et les règles d'alerte chargées.
- Alertmanager UI : Permet de voir les alertes actives, les silences configurés et l'état de la configuration du routage des alertes.
- SAS Environment Manager : Peut être utilisé pour vérifier la configuration de certains services Viya (par exemple, les loggers ) et potentiellement accéder aux outils de surveillance via les liens configurés.
Problèmes Courants et Scénarios
- Pods Bloqués en État "Pending" :
- Causes : Ressources insuffisantes dans le cluster pour satisfaire les requêtes du pod (CPU, mémoire) ; contraintes d'affinité ou taints/tolerations empêchant la planification sur les nœuds disponibles ; problèmes pour monter les volumes persistants requis ; échec du tirage de l'image de conteneur (image introuvable, problème d'authentification au registre).
- Diagnostic : Utiliser
kubectl describe pod <pod-name>pour consulter la section "Events" qui indique généralement la raison. Vérifier l'allocation des ressources sur les nœuds (kubectl describe node).
- Tableaux de Bord de Surveillance Vides ou Incomplets :
- Causes : Problèmes de scraping Prometheus (cibles "Down" dans l'UI Prometheus) ; exporters de métriques non fonctionnels ou mal configurés ; configuration incorrecte des ServiceMonitors/PodMonitors ; problèmes de connectivité réseau entre Prometheus et les pods/services cibles (vérifier les NetworkPolicies) ; problème de déploiement de V4M lui-même (par exemple, oubli d'exécuter
deploy_monitoring_viya.shpour le namespace Viya ) ; problème de permissions Grafana ou de sélection de la source de données. - Diagnostic : Vérifier l'état des cibles dans l'UI Prometheus. Examiner les logs des pods Prometheus et des exporters concernés. Vérifier que les ServiceMonitors/PodMonitors existent et sont corrects (
kubectl get servicemonitor,podmonitor -n <viya-namespace>). Tester la connectivité réseau. Consulter les issues GitHub de V4M pour des problèmes similaires.
- Causes : Problèmes de scraping Prometheus (cibles "Down" dans l'UI Prometheus) ; exporters de métriques non fonctionnels ou mal configurés ; configuration incorrecte des ServiceMonitors/PodMonitors ; problèmes de connectivité réseau entre Prometheus et les pods/services cibles (vérifier les NetworkPolicies) ; problème de déploiement de V4M lui-même (par exemple, oubli d'exécuter
- Problèmes de Logs :
- Causes : Logs n'apparaissant pas dans OpenSearch : Erreurs de configuration de Fluent Bit ; pods Fluent Bit (souvent un DaemonSet) qui plantent ou ne démarrent pas ; problèmes réseau entre Fluent Bit et OpenSearch ; cluster OpenSearch lui-même en mauvaise santé (disque plein, nœuds non disponibles).
- Diagnostic : Vérifier les logs des pods Fluent Bit (
kubectl logs -l app=fluent-bit -n logging). Vérifier l'état du cluster OpenSearch (via son API ou les tableaux de bord Grafana dédiés s'ils fonctionnent).
- Erreurs de Configuration V4M :
- Causes : Fautes de frappe, valeurs incorrectes ou format YAML invalide dans
user.envou les fichiers de personnalisation. - Diagnostic : Examiner attentivement les logs des scripts de déploiement V4M. Utiliser
kubectl get <resource-type> <resource-name> -o yamlpour inspecter la configuration réellement appliquée dans le cluster et la comparer avec les fichiers de personnalisation.
- Causes : Fautes de frappe, valeurs incorrectes ou format YAML invalide dans
- Problèmes de Déploiement Air-Gapped / Dark Site :
- Causes : Configuration incorrecte du registre privé dans les fichiers
user-values-*.yaml; images manquantes ou taguées incorrectement dans le registre privé ; problème avec le secret d'authentification (imagePullSecret) pour le registre privé. - Diagnostic : Suivre méticuleusement les étapes de déploiement air-gapped documentées. Vérifier les événements des pods en état
ImagePullBackOffouErrImagePull(kubectl describe pod). Vérifier manuellement l'accès au registre privé et la présence des images requises. Consulter les issues GitHub spécifiques aux déploiements air-gapped.
- Causes : Configuration incorrecte du registre privé dans les fichiers
- Problèmes de Performance des Composants de Surveillance :
- Causes : Prometheus, OpenSearch ou Grafana consomment trop de CPU/mémoire, impactant potentiellement Viya ou d'autres applications. Peut être dû à un sous-dimensionnement initial, une charge de métriques/logs très élevée, ou des requêtes Grafana/OpenSearch inefficaces.
- Diagnostic : Utiliser les tableaux de bord Grafana dédiés à la surveillance des composants de monitoring eux-mêmes. Analyser les requêtes lentes. Envisager d'ajuster les requêtes/limites des pods de surveillance ou de scaler horizontalement/verticalement ces composants si nécessaire.
Le dépannage efficace nécessite une double compétence : une bonne compréhension des outils spécifiques de la pile de surveillance (Prometheus, Grafana, OpenSearch, Fluent Bit) et de leur configuration dans V4M, ainsi qu'une maîtrise solide des concepts et des outils de diagnostic de Kubernetes (kubectl).
De nombreux problèmes courants trouvent leur origine dans des concepts fondamentaux de Kubernetes tels que la gestion des ressources (requêtes/limites), l'ordonnancement (affinités, taints/tolerations), le stockage persistant, la résolution DNS, la connectivité réseau (y compris les NetworkPolicies) et la gestion des images de conteneurs. Investir du temps dans l'apprentissage et la maîtrise de ces fondamentaux Kubernetes est donc indispensable pour quiconque est responsable de l'exploitation et du dépannage de la surveillance de SAS Viya. Se fier uniquement à la connaissance spécifique de SAS sera probablement insuffisant. Les ressources communautaires et GitHub sont particulièrement précieuses pour découvrir comment d'autres ont abordé et résolu des problèmes similaires dans des contextes réels.
Le mot de la fin (enfin presque...)
La surveillance efficace de SAS Viya sur Kubernetes est une composante critique de l'administration de la plateforme, garantissant sa performance, sa stabilité et sa fiabilité. Le passage à une architecture cloud-native conteneurisée impose l'adoption d'outils et de pratiques d'observabilité modernes.
A. Synthèse des Approches de Surveillance
- La solution SAS Viya Monitoring for Kubernetes (V4M), basée sur des standards open-source (Prometheus, Grafana, OpenSearch, Fluent Bit), est l'approche recommandée et supportée par SAS. Elle offre une couverture complète des logs et des métriques pour l'infrastructure Kubernetes et les composants SAS Viya.
- SAS Enterprise Session Monitor (ESM) peut compléter V4M en fournissant une analyse approfondie et orientée métier des sessions utilisateur (Programming et CAS), un domaine où V4M est moins spécialisé.
- Les outils natifs Kubernetes (
kubectl) restent essentiels pour les diagnostics de base et l'interaction directe avec le cluster. - L'intégration avec les outils de surveillance des fournisseurs cloud (Azure Monitor, CloudWatch, Google Monitoring) est une alternative viable, notamment pour les organisations ayant déjà standardisé sur ces plateformes.
Pour mettre en place une stratégie de surveillance robuste pour SAS Viya sur Kubernetes, les recommandations suivantes sont formulées :
- Adopter SAS Viya Monitoring for Kubernetes (V4M) : Utiliser V4M comme fondation de la stratégie de surveillance pour bénéficier d'une solution intégrée, supportée et spécifiquement adaptée à Viya.
- Investir dans les Compétences Kubernetes et Observabilité : S'assurer que les équipes responsables de la surveillance possèdent les compétences nécessaires en Kubernetes (concepts fondamentaux,
kubectl) et sur les outils open-source utilisés (Prometheus, Grafana, OpenSearch). - Planifier et Gérer la Configuration V4M : Ne pas se contenter des configurations par défaut. Planifier activement et personnaliser la configuration de V4M (rétention des données, sécurité, allocation des ressources, alertes) en fonction des besoins spécifiques de l'environnement. Utiliser des pratiques de gestion de configuration rigoureuses (par exemple, Git).
- Établir des Pratiques Opérationnelles : Mettre en place des routines pour la mise à jour régulière de V4M , la gestion de la sécurité de la pile de surveillance , et l'examen périodique des données de surveillance et des alertes générées.
- Exploiter les Ressources Communautaires : Utiliser activement les SAS Communities et le référentiel GitHub de V4M comme compléments à la documentation officielle pour le dépannage, l'apprentissage par l'exemple et pour rester informé des évolutions et des problèmes connus.
- Évaluer le Besoin de SAS ESM : Considérer le déploiement de SAS ESM en complément de V4M si une analyse détaillée des sessions utilisateur individuelles, de leur consommation de ressources et des workflows métier est une exigence critique.
- Se Concentrer sur les Métriques Essentielles : Mettre en place une surveillance couvrant toutes les couches pertinentes : infrastructure Kubernetes (nœuds, pods), applications SAS Viya (CAS, microservices, jobs), et services de support (PostgreSQL, RabbitMQ). Porter une attention particulière à l'utilisation des ressources (en distinguant requêtes et limites), à l'état des objets Kubernetes et aux indicateurs de performance spécifiques à Viya.
Conclusion (la vraie cette fois !)
La mise en œuvre d'une surveillance et d'une observabilité complètes est un investissement indispensable pour toute organisation exploitant SAS Viya en production sur Kubernetes. Elle permet non seulement de détecter et de résoudre proactivement les problèmes, mais aussi de comprendre le comportement de la plateforme, d'optimiser les performances, de planifier la capacité de manière éclairée et, in fine, de garantir la valeur métier délivrée par les puissantes capacités analytiques de SAS Viya. L'approche recommandée combine les outils fournis par SAS, une solide compréhension de Kubernetes, et l'engagement actif avec la communauté.



