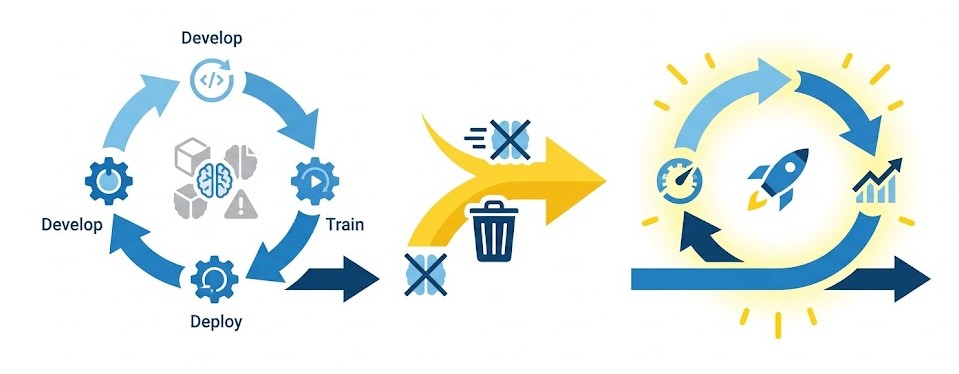
L'action prend en charge une architecture hybride très riche grâce à son paramètre externalOptions. La nature des sous-paramètres requis dépend entièrement de l'argument extType déclaré. Les systèmes cibles nativement supportés par les microservicesLes microservices sont une approche d'architecture logicielle où une application est décomposée en une collection de petits services indépendants, spécialisés et communicant entre eux via des APIs légères. Contrairement aux architectures "monolithiques" anciennes, chaque microservice remplit une fonction unique (ex: gestion du catalogue, authentification, moteur de calcul).
Dans SAS Viya 4, cette architecture est native. Elle permet à la plateforme de s'exécuter sur Kubernetes, offrant une flexibilité totale : chaque composant de SAS peut être mis à jour, redémarré ou mis à l'échelle (scaling) individuellement sans affecter le reste du système. de publication SAS incluent :
- HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data., Databricks et Synapse : Ils nécessitent principalement de spécifier la base de données ou le schéma cible où la table de modèles est stockée.
- TeradataSystème de gestion de base de données relationnelle hautement parallèle, conçu pour le stockage et l'analyse massive de données (Data Warehouse) en parfaite intégration avec SAS Viya. : Ce SGBD exige une configuration plus granulaire avec des options pour le domaine d'authentification, le nom du serveur et une sous-structure spécifique pour définir la table du modèleReprésentation mathématique entraînée sur des données pour capturer des tendances, prédire des résultats ou classifier des observations via des algorithmes (Régression, Forêt aléatoire, Gradient Boosting)..
- Filesystem : Utilisé pour les déploiements sur des systèmes de fichiers, il nécessite de pointer vers le répertoire racine du modèleReprésentation mathématique entraînée sur des données pour capturer des tendances, prédire des résultats ou classifier des observations via des algorithmes (Régression, Forêt aléatoire, Gradient Boosting). via le paramètre de répertoire associé.
- SingleStore : L'intégration est native et extrêmement fluide, ne nécessitant aucun paramètre additionnel au-delà de la définition de son type.