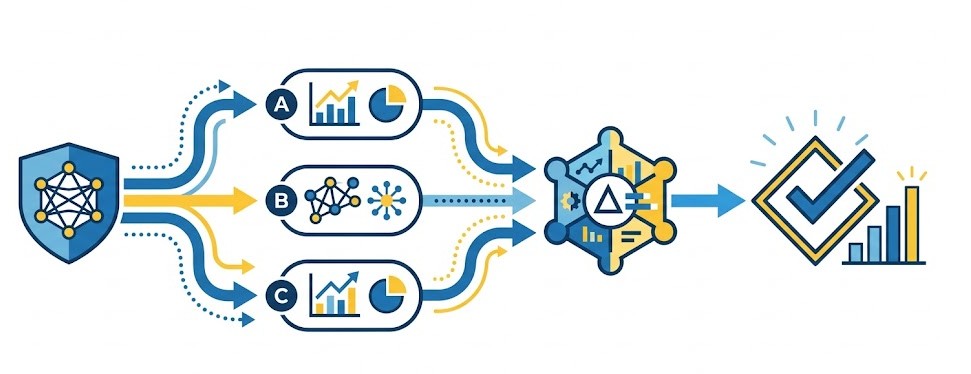
Absolument, le système repose sur une architecture découplée séparant l'entraînement de l'exécution. Le bloc de paramètres score a été conçu spécifiquement pour la mise en production et l'application d'une modélisationProcessus de création de structures mathématiques ou statistiques sur SAS Viya pour prédire des comportements, classifier des données ou identifier des tendances à partir de jeux de données CAS. préexistante sur un nouveau lot de données.
Lors de l'entraînement initial, vous devez d'abord sauvegarder les tables contenant les poids optimaux et les structures du modèleReprésentation mathématique entraînée sur des données pour capturer des tendances, prédire des résultats ou classifier des observations via des algorithmes (Régression, Forêt aléatoire, Gradient Boosting).. Ensuite, lors de l'appel de scoringProcessus d'application d'un modèle prédictif à de nouvelles données pour calculer une probabilité ou un score, permettant ainsi d'automatiser la prise de décision en temps réel sur SAS Viya. sur vos nouvelles bases de données, vous référencez simplement ces métadonnéesInformations décrivant les données, les utilisateurs et les ressources dans SAS Viya. Elles assurent la traçabilité, la sécurité et la gouvernance au sein de l'architecture distribuée. via les paramètres de tables d'entrée tels que inA, inB, inO et inPs. L'action appliquera l'ensemble des règles de calculs causaux complexes en mémoire de façon hautement optimisée et en une seule passe sur les nouvelles observations.