CAS et son cache disque
Si vous utilisez SAS Viya , vous pouvez avoir besoin de connaître les bases du fonctionnement de CAS pour utiliser pleinement le potentiel de SAS Viya. Vous trouverez de nombreux articles sur CAS sur mon blog (fonctionnement des sessions, chargement de table…). Cet article détail montre le fonctionnement , behind-the-scene, du CAS DISK CACHE
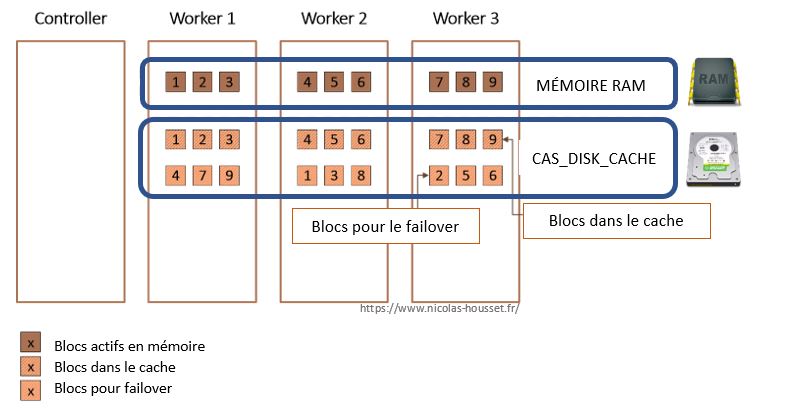 Si vous ajoutez une table à CAS vous créez des blocs.
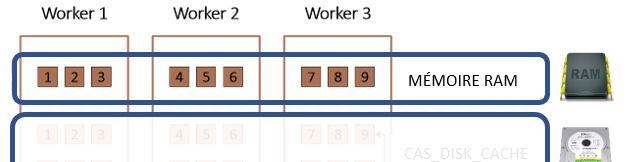
Les blocs actif sont les blocs utilisés par CAS (en RAM) :
Si vous ajoutez une table à CAS vous créez des blocs.
Les blocs actif sont les blocs utilisés par CAS (en RAM) :
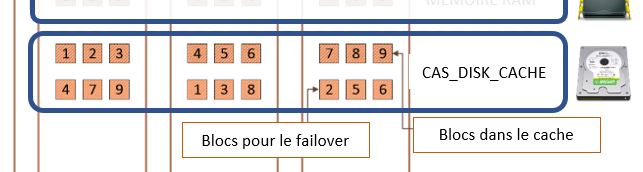
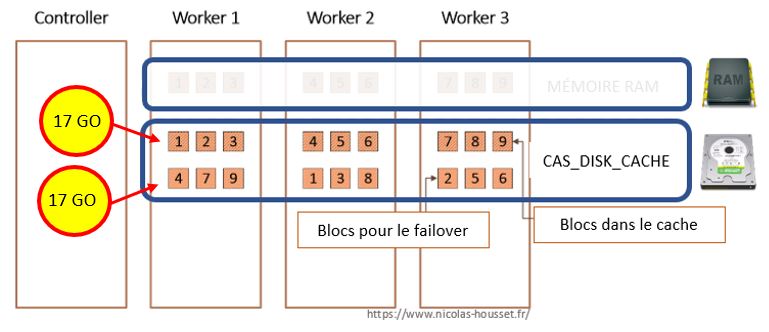
 Les blocs inactifs sont ceux sur le disque et ceux qu'il nous faudra peut-être activer en cas de défaillance d'un worker :
Les blocs inactifs sont ceux sur le disque et ceux qu'il nous faudra peut-être activer en cas de défaillance d'un worker :
 Chargement de la table dans une caslib :
Chargement de la table dans une caslib :
Journal SAS Studio :
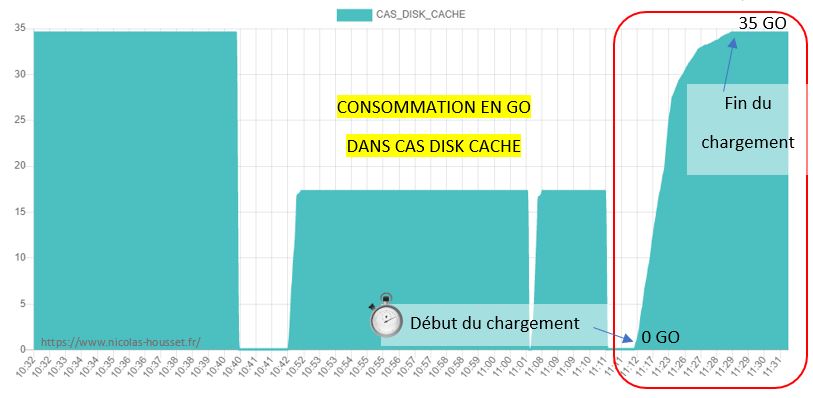
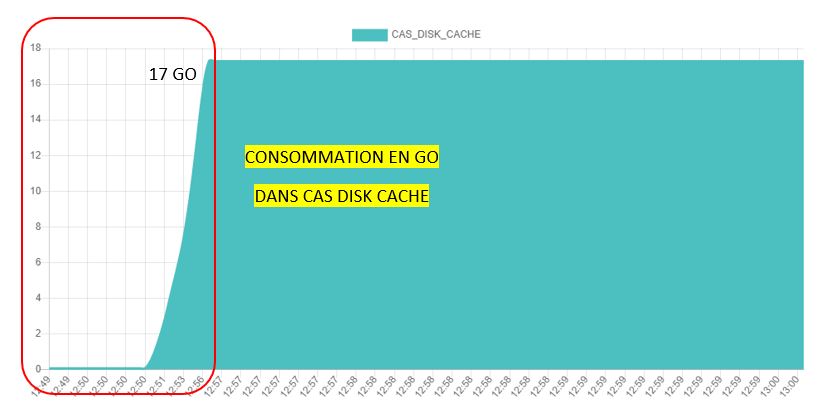
 Lorsque vous le chargez cette table, elle occupera environ 35 Go d’espace dans CAS_DISK_CACHE (La réplication par défaut est des 1) :
Lorsque vous le chargez cette table, elle occupera environ 35 Go d’espace dans CAS_DISK_CACHE (La réplication par défaut est des 1) :
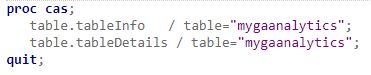
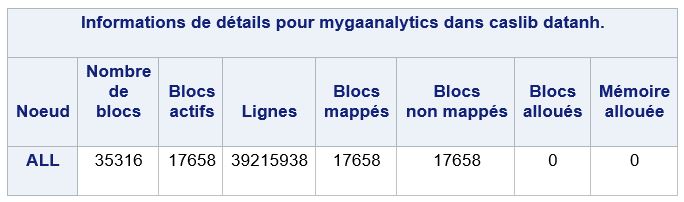
 Si l'on affiche les informations sur la table, via une proc cas table.tabledetails, il est possible d'avoir le détail des blocs mappés et non mappés ( utilisé pour le failover) :
Si l'on affiche les informations sur la table, via une proc cas table.tabledetails, il est possible d'avoir le détail des blocs mappés et non mappés ( utilisé pour le failover) :
 Et avec un paramètre de réplication à 0 ?
Et avec un paramètre de réplication à 0 ?
Journal SAS Studio :
 On constate l'absence de la ligne "octets déplacés" (qui était à 17,24 go avec une réplication à 1) et que le temps d’exécution est divisé par deux ( 246 secondes contre 503 secondes)
Sans réplication, les blocs ne sont pas doublés dans le cache ( pas de failover) :
On constate l'absence de la ligne "octets déplacés" (qui était à 17,24 go avec une réplication à 1) et que le temps d’exécution est divisé par deux ( 246 secondes contre 503 secondes)
Sans réplication, les blocs ne sont pas doublés dans le cache ( pas de failover) :
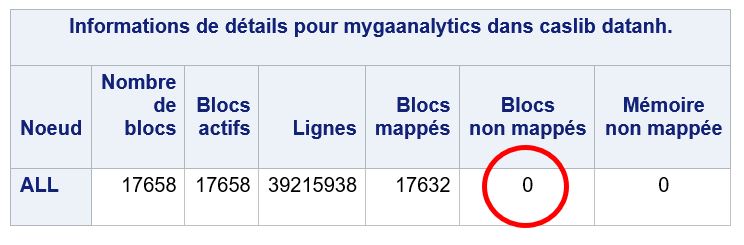
 Les détails de la table montre qu'il n'y a aucun blocs non mappés :
Les détails de la table montre qu'il n'y a aucun blocs non mappés :
Le CAS DISK CACHE, c'est quoi ?
L'un des principes de conception de Cloud Analytic Services (CAS) est de pouvoir gérer des problèmes complexes, de travailler avec des tables dépassant la capacité de mémoire de l'environnement, tout en restant réactif, rapide et de gérer les défaillances de nœud. Le cache CAS offre des fonctionnalités très utiles pour vous aider dans les situations où les ressources de performances principales (notamment la RAM) ont été épuisées. Laisser un processus aboutir, bien que lentement, est souvent préférable à un échec total. CAS par rapport à LASR est la possibilité d'utiliser un cache comme magasin de sauvegarde pour les données en mémoire. Le cache CAS offre une flexibilité pour les opérations en mémoire, garantissant que CAS:- Maintient la disponibilité des tables lorsque plus de données sont chargées que la RAM physique disponible,
- Fournit une protection de reprise en ligne si un agent CAS passe hors ligne de manière inattendue,
- S'appuie sur les descripteurs de fichier des blocs SASHDAT mappés en mémoire pour fournir le mécanisme permettant à plusieurs sessions CAS d'accéder à la même instance de données
Quel espace est nécessaire pour le CAS DISK CACHE ?
Toute opération qui charge ou crée des données dans CAS utilise l'emplacement CAS_DISK_CACHE, donc :- La taille doit correspondre à la taille totale des tables dans CAS.
- Ces besoins en espace doivent prendre en compte à la fois les tables chargées et les tables créées en tant que sorties des actions CAS.
- Le calcul doit inclure les copies utilisées pour le failover (voir les exemples de cet article).
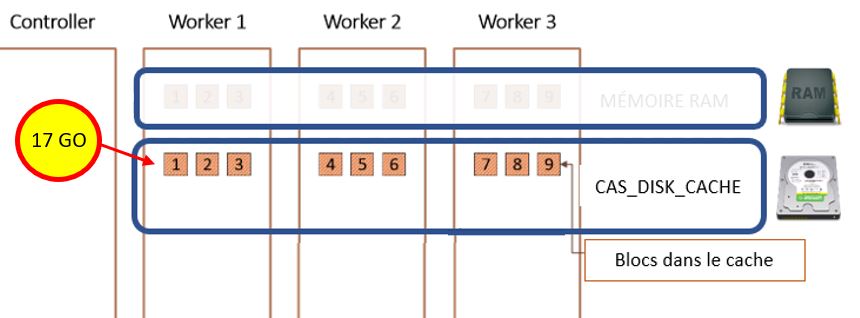
Des blocs ?
Un dernier point que je voulais aborder avant de passer aux exemples. Les données d'une table CAS sont constituées de blocs.Afin d'éviter la perte de données, les blocs sont répliqués entre les worker dans le cas où un worker ne serait pas disponible.
Si vous ajoutez une table à CAS vous créez des blocs.
Les blocs actif sont les blocs utilisés par CAS (en RAM) :
Les blocs inactifs sont ceux sur le disque et ceux qu'il nous faudra peut-être activer en cas de défaillance d'un worker :
Exemples
Pour mes exemples, je vais utiliser une table (sas7bdat) de 17 go que je vais charger dans une CASLIB :
Chargement de la table dans une caslib :
|
1 2 3 4 |
proc casutil; load casdata="mygaanalytics.sas7bdat" incaslib="datanh" outcaslib="datanh" casout="mygaanalyticst" replace ; run; |
Lorsque vous le chargez cette table, elle occupera environ 35 Go d’espace dans CAS_DISK_CACHE (La réplication par défaut est des 1) :
Si l'on affiche les informations sur la table, via une proc cas table.tabledetails, il est possible d'avoir le détail des blocs mappés et non mappés ( utilisé pour le failover) :
Et avec un paramètre de réplication à 0 ?
|
1 2 3 4 |
proc casutil; load casdata="mygaanalytics.sas7bdat" incaslib="datanh" outcaslib="datanh" casout="mygaanalytics" replication=0; run; |
On constate l'absence de la ligne "octets déplacés" (qui était à 17,24 go avec une réplication à 1) et que le temps d’exécution est divisé par deux ( 246 secondes contre 503 secondes)
Sans réplication, les blocs ne sont pas doublés dans le cache ( pas de failover) :
Les détails de la table montre qu'il n'y a aucun blocs non mappés :