La gestion efficace du placement des pods (unités d'exécution de KubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya.) sur les nœuds d'un clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. est cruciale pour optimiser les performances, assurer l'isolation des charges de travail et gérer les ressources. Les taints et les tolérances sont des mécanismes fondamentaux de KubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya., et par extension d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site., qui permettent de contrôler finement ce placement.
Concepts Fondamentaux : Taints, Tolérances et Effets
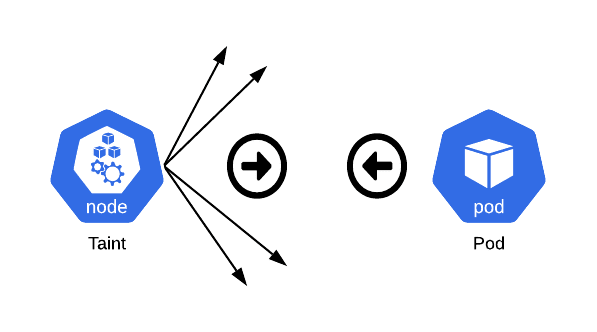
Un taint est une propriété appliquée à un nœud. Il agit comme une marque qui repousse un ensemble de pods. Un nœud peut avoir un ou plusieurs taints. Chaque taint est composé d'une clé (key), d'une valeur (value) et d'un effet (effect). L'effet spécifie comment le planificateur (scheduler) doit traiter les pods qui ne tolèrent pas ce taint.
Une tolérance est une propriété appliquée à un pod. Elle permet au pod d'être planifié sur un nœud possédant des taints correspondants. Les tolérances permettent la planification mais ne la garantissent pas, car le planificateur évalue également d'autres paramètres.
Les trois principaux effets de taint sont :
-
NoSchedule: Si un pod ne tolère pas un taint avec l'effetNoSchedulesur un nœud, le planificateur ne placera pas ce pod sur ce nœud. Les pods déjà en cours d'exécution sur le nœud ne sont pas affectés. PreferNoSchedule: Le planificateur essaiera d'éviter de placer un pod qui ne tolère pas ce taint sur le nœud. Cependant, s'il n'y a pas d'autre nœud disponible, le pod pourra y être planifié.NoExecute: Cet effet est plus strict. Non seulement il empêche la planification de nouveaux pods ne tolérant pas le taint, mais il expulse également les pods déjà en cours d'exécution sur le nœud qui ne le tolèrent pas. Un paramètretolerationSecondspeut être spécifié dans la tolérance du pod pour indiquer une période de grâce avant l'expulsion.
OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. intègre des taints prédéfinis qui sont automatiquement appliqués par le contrôleur de nœuds (Node Controller) en réponse à certaines conditions du nœud, comme node.kubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya..io/not-ready (nœud non prêt), node.kubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya..io/unreachable (nœud injoignable), ou node.kubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya..io/memory-pressure (pression mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. sur le nœud).
Mécanisme d'Action : Comment les Taints et Tolérances Contrôlent la Planification des Pods
Lorsqu'un pod doit être planifié, le planificateur de KubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya./OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. examine les taints présents sur les nœuds disponibles et les tolérances définies dans la spécification du pod. Un pod ne peut être planifié sur un nœud que s'il tolère tous les taints du nœud qui ont un effet restrictif (comme NoSchedule ou NoExecute).
La correspondance entre un taint et une tolérance dépend de l'opérateur spécifié dans la tolérance :
-
Equal: La clé, la valeur et l'effet du taint doivent correspondre à ceux de la tolérance. Exists: Seuls la clé et l'effet doivent correspondre. La valeur du taint peut être quelconque, et la tolérance ne spécifie pas de valeur.
Un nœud peut avoir plusieurs taints, et un pod peut avoir plusieurs tolérances. OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. traite ces configurations multiples en vérifiant d'abord les taints pour lesquels le pod a une tolérance correspondante. Les effets des taints restants (non appariés) sont ensuite appliqués au pod. Par exemple, s'il reste au moins un taint non apparié avec l'effet NoSchedule, le pod ne sera pas planifié sur ce nœud.
Synergie avec l'Affinité de Nœud et les Sélecteurs
Il est important de distinguer les taints/tolérances de l'affinité de nœud (node affinity) et des sélecteurs de nœud (node selectors).
![]()
Les taints permettent à un nœud de repousser des pods,
![]()
L'affinité de nœud est une propriété des pods qui les attire vers un ensemble de nœuds.
![]()
Les sélecteurs de nœud permettent de contraindre un pod à ne s'exécuter que sur des nœuds possédant des labels spécifiques.
Les taints et tolérances offrent un contrôle plus granulaire que l'anti-affinité de pod. Pour créer des nœuds véritablement dédiés à des charges de travail spécifiques – une pratique recommandée pour SAS Viya – il est courant de combiner les taints et tolérances avec l'affinité de nœud et les labels de nœud. Par exemple, on peut appliquer un taint à un ensemble de nœuds pour repousser tous les pods non désirés, donner aux pods SAS Viya ciblés la tolérance correspondante, et utiliser l'affinité de nœud pour s'assurer que ces pods SAS Viya sont activement attirés et planifiés uniquement sur ces nœuds dédiés.
Cette approche combinée est particulièrement pertinente pour SAS Viya. Les taints servent de mécanisme de contrôle "négatif", repoussant les pods indésirables des nœuds spécialisés.
Cependant, se fier uniquement aux taints ne garantit pas qu'un pod atterrira sur un nœud spécifique si plusieurs nœuds correspondent à ses tolérances et que d'autres critères de planification sont remplis.
L'affinité de nœud, utilisant des labels, fournit le contrôle "positif" nécessaire pour diriger activement les pods vers les nœuds souhaités.
Pour garantir qu'un pod s'exécute uniquement sur un ensemble spécifique de nœuds et qu'aucun autre pod ne s'y exécute, la combinaison de taints (sur les nœuds), de tolérances (sur les pods souhaités) et d'affinité de nœud (sur les pods souhaités correspondant aux labels des nœuds dédiés) constitue la stratégie la plus robuste.
L'effet de taint NoExecute a des implications opérationnelles significatives car il peut entraîner l'expulsion de pods. Bien que bénéfique pour la maintenance des nœuds ou pour réagir à des problèmes de nœuds, cet effet nécessite une gestion prudente pour éviter les perturbations involontaires. Le paramètre tolerationSeconds offre une période de grâce , permettant aux pods de terminer leur travail ou de donner du temps au problème pour se résoudre avant l'expulsion. Pour les applications avec état, comme certains composants de SAS Viya, des expulsions inattendues peuvent être problématiques si elles ne sont pas correctement gérées avec la gestion de l'état et le stockage persistant. Ainsi, la compréhension et la configuration minutieuse de tolerationSeconds pour les pods SAS critiques deviennent importantes.
Architecture des Charges de Travail SAS Viya 4SAS Viya 4 est une plateforme d'IA, de data management et d'analytics de pointe, nativement conçue pour le Cloud (Cloud-Native). Contrairement aux versions précédentes, elle repose sur une architecture de microservices orchestrée par Kubernetes.
Elle permet de gérer l'intégralité du cycle de vie de la donnée — de l'ingestion à la mise en production des modèles (ModelOps) — en offrant une élasticité totale, une intégration transparente avec l'open-source (Python, R) et une interface unifiée pour les data scientists et les décideurs métiers. sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.
SAS Viya 4SAS Viya 4 est une plateforme d'IA, de data management et d'analytics de pointe, nativement conçue pour le Cloud (Cloud-Native). Contrairement aux versions précédentes, elle repose sur une architecture de microservices orchestrée par Kubernetes.
Elle permet de gérer l'intégralité du cycle de vie de la donnée — de l'ingestion à la mise en production des modèles (ModelOps) — en offrant une élasticité totale, une intégration transparente avec l'open-source (Python, R) et une interface unifiée pour les data scientists et les décideurs métiers. est une plateforme analytique intégrée, conçue comme une suite d'applications et de services plutôt que comme une application monolithique. Son architecture moderne, basée sur des conteneurs et des microservicesLes microservices sont une approche d'architecture logicielle où une application est décomposée en une collection de petits services indépendants, spécialisés et communicant entre eux via des APIs légères. Contrairement aux architectures "monolithiques" anciennes, chaque microservice remplit une fonction unique (ex: gestion du catalogue, authentification, moteur de calcul).
Dans SAS Viya 4, cette architecture est native. Elle permet à la plateforme de s'exécuter sur Kubernetes, offrant une flexibilité totale : chaque composant de SAS peut être mis à jour, redémarré ou mis à l'échelle (scaling) individuellement sans affecter le reste du système., tire pleinement parti des capacités d'orchestration de KubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya., et donc d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.. Cette architecture modulaire présente des caractéristiques de charge de travail variées, ce qui influence directement la manière dont les ressources du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. doivent être configurées et gérées.
Vue d'ensemble des Classes de Charges de Travail SAS Viya (CAS, Compute, Stateless, Stateful Une app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé., Connect)
Une app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé., Connect)
SAS Viya se décompose en plusieurs classes de charges de travail distinctes, chacune ayant des exigences spécifiques en termes de ressources (CPU, mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya., E/S, GPU) et de comportement :
- SAS Cloud Analytic ServicesMoteur analytique distribué et en mémoire (in-memory) au cœur de SAS Viya. Il assure le traitement des données et l'exécution des modèles avec une très haute performance. (CAS): C'est le moteur d'analyse en mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. au cœur de SAS Viya. Il est extrêmement intensif en CPU et en mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya., et nécessite un stockage persistant performant (pour CAS_DISK_CACHEEspace de stockage local temporaire utilisé par le serveur CAS pour gérer les données dépassant la RAM disponible ou pour mapper des fichiers, garantissant ainsi la performance des traitements.) accessible par tous les pods CAS. CAS peut fonctionner en mode SMPLe Symmetric Multi-Processing (SMP) est une architecture informatique où plusieurs processeurs (CPU) partagent une mémoire centrale unique et un seul système d'exploitation pour exécuter des tâches. Contrairement au mode MPP, toutes les opérations se déroulent au sein d'une seule machine ou d'un seul nœud de calcul.
Dans l'écosystème SAS Viya 4, le mode SMP est idéal pour les jeux de données de taille petite à moyenne ou pour les phases de préparation de code. Le moteur CAS (Cloud Analytic Services) utilise alors la puissance multi-cœurs d'un nœud unique pour traiter les données avec une latence minimale. (Symmetric Multi Processing), avec une seule instance, ou en mode MPPLe Massively Parallel Processing (MPP) est une architecture informatique où plusieurs processeurs (ou nœuds de calcul) travaillent simultanément sur différentes parties d'une même tâche complexe. Contrairement au traitement séquentiel, le MPP divise les données en fragments gérés en parallèle, réduisant drastiquement le temps d'exécution.
Dans l'écosystème SAS Viya 4, l'architecture MPP est incarnée par le moteur CAS (Cloud Analytic Services). Elle permet de distribuer les calculs analytiques et d'IA sur l'ensemble d'un cluster Kubernetes ou OpenShift, offrant une puissance de traitement quasi illimitée pour les Big Data. (Massive Parallel Processing), distribué sur plusieurs pods (un contrôleur et des workers). Par défaut, CAS est conçu pour consommer une part très importante des ressources du nœud sur lequel il s'exécute (souvent plus de 90%). - SAS Compute Services (Compute): Ces services représentent les capacités de traitement SAS traditionnelles, utilisées pour les sessions SAS interactives (par exemple, depuis SAS Studio) et les travaux batch. Les sessions de calcul sont hautement parallélisables et peuvent générer une charge fluctuante, ce qui en fait un bon candidat pour l'autoscaling du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle..
- SAS MicroservicesLes microservices sont une approche d'architecture logicielle où une application est décomposée en une collection de petits services indépendants, spécialisés et communicant entre eux via des APIs légères. Contrairement aux architectures "monolithiques" anciennes, chaque microservice remplit une fonction unique (ex: gestion du catalogue, authentification, moteur de calcul).
Dans SAS Viya 4, cette architecture est native. Elle permet à la plateforme de s'exécuter sur Kubernetes, offrant une flexibilité totale : chaque composant de SAS peut être mis à jour, redémarré ou mis à l'échelle (scaling) individuellement sans affecter le reste du système. et Applications Web (Stateless): La majorité des services de SAS Viya sont conçus comme des microservicesLes microservices sont une approche d'architecture logicielle où une application est décomposée en une collection de petits services indépendants, spécialisés et communicant entre eux via des APIs légères. Contrairement aux architectures "monolithiques" anciennes, chaque microservice remplit une fonction unique (ex: gestion du catalogue, authentification, moteur de calcul).
Dans SAS Viya 4, cette architecture est native. Elle permet à la plateforme de s'exécuter sur Kubernetes, offrant une flexibilité totale : chaque composant de SAS peut être mis à jour, redémarré ou mis à l'échelle (scaling) individuellement sans affecter le reste du système. suivant les principes des "12 factor apps". Ils fournissent des services centraux (audit, authentification, etc.) ainsi que les interfaces utilisateur web (SAS Visual Analytics, SAS Model Manager, etc.). Ces composants sont généralement moins gourmands en ressources individuellement et peuvent être mis à l'échelle horizontalement pour la haute disponibilité et la gestion de la charge. - Services d'Infrastructure (StatefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.): Cette catégorie regroupe les composants qui gèrent le stockage des métadonnéesInformations décrivant les données, les utilisateurs et les ressources dans SAS Viya. Elles assurent la traçabilité, la sécurité et la gouvernance au sein de l'architecture distribuée. et l'état opérationnel de la plateforme, tels que la base de données PostgreSQL interne à SAS, Consul pour la découverte de services et RabbitMQ pour la messagerie. Ces services nécessitent un stockage persistant fiable et sont souvent intensifs en opérations d'E/S.
- SAS/CONNECT Services (Connect): Ces services facilitent la communication et le transfert de données entre différentes sessions SAS ou entre SAS Viya et d'autres systèmes SAS. La classification de cette charge de travail a évolué ; elle est désormais souvent traitée comme faisant partie des services stateless, à moins que des clients SAS/CONNECT "legacy" (plus anciens) ne soient utilisés, auquel cas une configuration spécifique peut être nécessaire.
Le Rôle des Pools de Nœuds dans les Déploiements SAS Viya
Pour gérer efficacement ces diverses charges de travail, SAS recommande fortement d'assigner chaque classe de charge de travail à des ensembles de nœuds dédiés, appelés pools de nœuds (node pools) ou, dans le contexte OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site., souvent gérés via des ensembles de machines (MachineSets).
Les avantages de cette approche sont multiples :
- Adaptation des Configurations Matérielles: Permet d'utiliser des types de nœuds (machines virtuelles ou physiques) avec des configurations matérielles spécifiques (plus de CPU/mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. pour CAS, des GPU pour certaines tâches de calcul, du stockage haute performance pour les services statefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.) adaptées aux besoins de chaque charge de travail. - Amélioration des Performances et de la Stabilité: En isolant les charges de travail, on évite les interférences et la contention des ressources ("noisy neighbor problem"), ce qui conduit à des performances plus prévisibles et à une meilleure stabilité globale de la plateforme SAS Viya.
- Gestion Optimisée des Ressources: Facilite la surveillance, l'allocation et l'optimisation des ressources du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle..
Un déploiement typique de SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. nécessitera au minimum un pool de nœuds par défaut (ou système, pour les composants OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. et non-SAS) et au moins deux pools de nœuds utilisateurs, dont l'un doit être entièrement dédié aux serveurs CAS.
SAS recommande souvent une configuration avec 5 pools : un par défaut, et un pour chacune des classes de charge principales (CAS, Compute, Stateless, Stateful
La recommandation de pools de nœuds distincts pour les charges de travail SAS Viya n'est pas une simple suggestion organisationnelle, mais une exigence fondamentale pour atteindre les niveaux de performance, de stabilité et d'utilisation efficace des ressources attendus.
Cela est particulièrement vrai compte tenu du profil de consommation de ressources agressif de composants comme CAS.
Les composants SAS Viya ont des besoins hétérogènes en ressources : CAS est gourmand en mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya./CPU, les services statefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé. sont liés aux E/S, et le calcul peut être en rafales. CAS, par conception, tente d'utiliser environ 90-95% des ressources d'un nœud. Le co-localiser avec d'autres charges de travail importantes sans contrôles stricts entraînerait inévitablement une pénurie de ressources. Les pools de nœuds permettent d'adapter le matériel (par exemple, des nœuds à haute mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. pour CAS, des nœuds GPU pour des tâches de calcul spécifiques) à ces divers besoins. Les taints et tolérances sont le mécanisme KubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya. qui permet d'appliquer cette séparation sur les pools de nœuds désignés. Par conséquent, les pools de nœuds constituent le regroupement physique/logique, et les taints/tolérances sont le mécanisme d'application de l'architecture distribuée recommandée par SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site..
CAS, par conception, tente d'utiliser environ 90-95% des ressources d'un nœud. Le co-localiser avec d'autres charges de travail importantes sans contrôles stricts entraînerait inévitablement une pénurie de ressources
Tableau : Classes de Charges de Travail SAS Viya et Caractéristiques Recommandées des Pools de Nœuds
Classe de Charge de TravailFonction PrincipaleDemandes Clés en RessourcesProfil Matériel de Nœud RecommandéTaint Typique Appliqué (Exemple)CASMoteur d'analyse en mémoireCPU élevé, MémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. élevée, E/S disqueNœuds avec beaucoup de CPU/RAM, stockage local rapide (NVMe/SSD)workload.sas.com/class=cas:NoScheduleComputeExécution de code SAS (interactif, batch)CPU, MémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. (fluctuant)Nœuds avec bon ratio CPU/RAM, potentiellement GPUworkload.sas.com/class=compute:NoScheduleStatelessApplications Web, microservicesCPU modéré, MémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. modéréeNœuds à usage généralworkload.sas.com/class=stateless:NoScheduleStatefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.Services d'infrastructure (BDD, messagerie, etc.)E/S disque, MémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. modéréeNœuds avec stockage persistant fiable et performantworkload.sas.com/class=stateful Ce tableau consolide des informations cruciales, aidant les administrateurs à comprendre le "pourquoi" derrière les configurations spécifiques des pools de nœuds et les stratégies de taint. Il relie la structure interne de SAS Viya aux décisions d'infrastructure OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.Une app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.:NoSchedule
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site., fournissant une justification claire pour l'allocation des ressources et les politiques d'isolation.
Application Stratégique des Taints et Tolérances pour les Charges de Travail SAS Viya
L'utilisation des taints et tolérances dans un déploiement SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. n'est pas une simple option de configuration, mais une composante stratégique essentielle pour garantir que l'architecture complexe de SAS Viya fonctionne de manière optimale sur la plateforme d'orchestration.
Justification de l'Utilisation des Taints dans SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.
L'application de taints aux nœuds OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. dans un contexte SAS Viya répond à plusieurs impératifs :
- Application de la Stratégie de Placement des Charges de Travail: Assurer que les différents composants de SAS Viya s'exécutent sur des nœuds disposant des ressources (CPU, mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya., GPU, type de stockage) et des configurations adéquates, conformément à l'architecture recommandée par SAS. - Isolation des Ressources et Prévention des Interférences: Empêcher que des charges de travail non-SAS, ou même des charges de travail SAS inappropriées, ne consomment les ressources critiques des nœuds dédiés, en particulier ceux alloués aux serveurs CAS. Cela évite le phénomène de "voisin bruyant" et garantit les performances.
- Spécialisation Matérielle: Faciliter la dedication de nœuds dotés de matériel spécialisé, comme des GPU, à des charges de travail SAS spécifiques qui peuvent en tirer parti (par exemple, certaines routines analytiques dans CAS ou des tâches de deep learningSous-ensemble du Machine Learning basé sur des réseaux de neurones artificiels profonds. Il excelle dans l'extraction automatique de motifs complexes depuis des données brutes (images, texte, son). dans SAS Visual Data Mining and Machine LearningBranche de l'IA utilisant des algorithmes pour apprendre des modèles à partir de données. Il permet d'automatiser des prédictions ou des décisions sans programmation explicite de chaque règle.).
Dedication des Nœuds CAS : Garantir Performance et Isolation
Les serveurs CAS sont le cœur analytique de SAS Viya et leurs performances sont critiques. Ils sont conçus pour utiliser intensivement les ressources des nœuds sur lesquels ils s'exécutent. Par conséquent, il est impératif de leur dédier des nœuds et d'utiliser des taints pour les isoler :
- Les taints sont essentiels pour empêcher d'autres pods d'être planifiés sur les nœuds CAS.
- Les pods CAS doivent impérativement posséder la tolérance correspondante pour pouvoir être planifiés sur ces nœuds.
- La fonctionnalité d'auto-allocation des ressources de CAS (CAS auto-resourcing), qui permet à CAS d'ajuster dynamiquement son utilisation des ressources en fonction de ce qui est disponible sur le nœud (visant souvent 95% de CPU et mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya.), repose sur le fait que ces nœuds sont correctement labellisés et "taintés" comme étant dédiés à CAS.
Gestion des Charges de Travail de Calcul (Compute) pour la Scalabilité et l'Optimisation des Ressources
Les services de calcul SAS (SAS Compute Services) gèrent les sessions de programmation SAS et les travaux batch. Ces charges de travail peuvent être variablesColonnes d'une table SAS contenant des données spécifiques (numériques ou caractères). Elles possèdent des attributs comme le nom, le type, la longueur, l'étiquette et le format d'affichage. et bénéficier d'une gestion dédiée :
- Les nœuds de calcul peuvent être "taintés" pour leur dédier des ressources spécifiques.
- Les pods de calcul SAS (comme ceux lancés par SAS Studio ou les jobs batch) auront les tolérances nécessaires pour ces taints.
- Cette approche permet d'allouer des profils matériels spécifiques aux nœuds de calcul (par exemple, avec plus de mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. ou des GPU pour certaines tâches) et de mettre en place des stratégies d'autoscaling pour ce pool de nœuds afin de s'adapter dynamiquement à la demande.
Traitement des Services Stateless et StatefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.
Les services stateless (applications web, microservicesLes microservices sont une approche d'architecture logicielle où une application est décomposée en une collection de petits services indépendants, spécialisés et communicant entre eux via des APIs légères. Contrairement aux architectures "monolithiques" anciennes, chaque microservice remplit une fonction unique (ex: gestion du catalogue, authentification, moteur de calcul).
Dans SAS Viya 4, cette architecture est native. Elle permet à la plateforme de s'exécuter sur Kubernetes, offrant une flexibilité totale : chaque composant de SAS peut être mis à jour, redémarré ou mis à l'échelle (scaling) individuellement sans affecter le reste du système.) et statefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé. (bases de données, services de messagerie) de SAS Viya peuvent également être ciblés vers des pools de nœuds dédiés via des taints :
- Des taints peuvent être appliqués aux pools de nœuds respectifs.
- Les pods SAS Viya correspondants possèdent les tolérances appropriées. Une particularité intéressante est que, par défaut, les pods stateless tolèrent souvent les taints des nœuds statefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé., et vice-versa. Cela offre une certaine flexibilité de placement initial, mais peut nécessiter un ajustement si une isolation stricte est requise.
Configurations Spécifiques des Taints et Tolérances pour SAS Viya
Le schéma de taints principal utilisé par SAS pour le placement des charges de travail est basé sur la clé workload.sas.com/class. Les valeurs associées à cette clé identifient la nature de la charge de travail (par exemple, cas, compute, stateless, stateful, Une app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.connect, et des distinctions plus fines comme cascontroller, casworker pour les déploiements MPPLe Massively Parallel Processing (MPP) est une architecture informatique où plusieurs processeurs (ou nœuds de calcul) travaillent simultanément sur différentes parties d'une même tâche complexe. Contrairement au traitement séquentiel, le MPP divise les données en fragments gérés en parallèle, réduisant drastiquement le temps d'exécution.
Dans l'écosystème SAS Viya 4, l'architecture MPP est incarnée par le moteur CAS (Cloud Analytic Services). Elle permet de distribuer les calculs analytiques et d'IA sur l'ensemble d'un cluster Kubernetes ou OpenShift, offrant une puissance de traitement quasi illimitée pour les Big Data. CAS). L'effet de taint le plus couramment recommandé et utilisé est NoSchedule.
La stratégie de tolérance par défaut de SAS pour les pods stateless et statefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé. (tolérant mutuellement leurs taints respectifs) offre une flexibilité de déploiement initiale.
Cependant, elle pourrait nécessiter un affinement pour une isolation stricte des charges de travail dans des environnements aux ressources limitées ou hautement optimisés. Si un pool de nœuds 'stateless' est plein, les pods stateless pourraient potentiellement être planifiés sur des nœuds 'statefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.' si ces nœuds ont de la capacité et qu aucun autre taint ne l empêche (et vice-versa).
Bien que cela puisse empêcher les pods de rester en attente si leur pool principal est plein, cela peut diluer l'isolation prévue des charges de travail. La documentation SAS mentionne une option pour une "planification stricte statefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé. et stateless" en supprimant ces tolérances croisées, indiquant une prise de conscience de ce compromis.
Par conséquent, les administrateurs doivent décider si cette flexibilité par défaut est souhaitée ou si une isolation plus stricte est nécessaire pour leurs objectifs spécifiques de performance et de gestion des ressources.
Cependant, elle pourrait nécessiter un affinement pour une isolation stricte des charges de travail dans des environnements aux ressources limitées ou hautement optimisés.
Si un pool de nœuds 'stateless' est plein, les pods stateless pourraient potentiellement être planifiés sur des nœuds 'statefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.' si ces nœuds ont de la capacité et qu aucun autre taint ne l empêche (et vice-versa).
Bien que cela puisse empêcher les pods de rester en attente si leur pool principal est plein, cela peut diluer l'isolation prévue des charges de travail. La documentation SAS mentionne une option pour une "planification stricte statefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé. et stateless" en supprimant ces tolérances croisées, indiquant une prise de conscience de ce compromis.
Par conséquent, les administrateurs doivent décider si cette flexibilité par défaut est souhaitée ou si une isolation plus stricte (nécessitant la suppression de ces tolérances croisées et potentiellement une planification plus minutieuse de la capacité par pool) est nécessaire pour leurs objectifs spécifiques de performance et de gestion des ressources.
L'effet NoSchedule est principalement recommandé par SAS pour ses taints de classe de charge de travail. Cela implique une stratégie axée sur la prévention d'un placement initial incorrect plutôt que sur l'expulsion active de pods déjà en cours d'exécution (mais peut-être mal placés), ce que ferait NoExecute. NoSchedule n'affecte que la planification des nouveaux pods ; les pods existants ne sont pas expulsés si un taint NoSchedule est ajouté ou s'ils ont été planifiés avant le taint. Cela suggère que l'objectif principal de SAS avec ces taints est de guider le planificateur lors des événements de déploiement et de mise à l'échelle pour placer correctement les pods dès le départ. Si des pods étaient d'une manière ou d'une autre mal placés sur des nœuds où ils ne devraient pas être (par exemple, en raison d'une mauvaise configuration temporaire ou d'un remplacement manuel), un taint NoSchedule seul ne corrigerait pas cela pour les pods déjà en cours d'exécution. NoExecute serait nécessaire pour une telle expulsion corrective, mais ce n'est pas la recommandation standard de SAS pour ces taints de charge de travail, ce qui implique une focalisation sur le placement correct proactif.
Tableau : Clés de Taint, Valeurs et Effets Recommandés pour les Classes de Charges de Travail SAS Viya
Classe de Charge SAS ViyaLabel de Pool de Nœuds CorrespondantClé de TaintValeur de TaintEffet de TaintObjectif/JustificationCASworkload.sas.com/class=casworkload.sas.com/classcasNoScheduleDédier les nœuds aux serveurs CAS, intensifs en ressources.Computeworkload.sas.com/class=computeworkload.sas.com/classcomputeNoScheduleDédier les nœuds aux sessions de calcul SAS et travaux batch.Statelessworkload.sas.com/class=statelessworkload.sas.com/classstatelessNoScheduleDédier les nœuds aux applications web et microservicesLes microservices sont une approche d'architecture logicielle où une application est décomposée en une collection de petits services indépendants, spécialisés et communicant entre eux via des APIs légères. Contrairement aux architectures "monolithiques" anciennes, chaque microservice remplit une fonction unique (ex: gestion du catalogue, authentification, moteur de calcul).
Dans SAS Viya 4, cette architecture est native. Elle permet à la plateforme de s'exécuter sur Kubernetes, offrant une flexibilité totale : chaque composant de SAS peut être mis à jour, redémarré ou mis à l'échelle (scaling) individuellement sans affecter le reste du système. SAS.StatefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.workload.sas.com/class=statefulworkload.sas.com/classstatefulNoScheduleDédier les nœuds aux services d'infrastructure SAS nécessitant un état persistant.Connect (optionnel)workload.sas.com/class=connectworkload.sas.com/classconnectNoScheduleDédier les nœuds aux services SAS/CONNECT, si des clients hérités sont utilisés.CAS Controller (MPPLe Massively Parallel Processing (MPP) est une architecture informatique où plusieurs processeurs (ou nœuds de calcul) travaillent simultanément sur différentes parties d'une même tâche complexe. Contrairement au traitement séquentiel, le MPP divise les données en fragments gérés en parallèle, réduisant drastiquement le temps d'exécution.
Dans l'écosystème SAS Viya 4, l'architecture MPP est incarnée par le moteur CAS (Cloud Analytic Services). Elle permet de distribuer les calculs analytiques et d'IA sur l'ensemble d'un cluster Kubernetes ou OpenShift, offrant une puissance de traitement quasi illimitée pour les Big Data.)workload.sas.com/class=cascontrollerworkload.sas.com/classcascontrollerNoScheduleDédier des nœuds spécifiques pour les contrôleurs CAS en mode MPPLe Massively Parallel Processing (MPP) est une architecture informatique où plusieurs processeurs (ou nœuds de calcul) travaillent simultanément sur différentes parties d'une même tâche complexe. Contrairement au traitement séquentiel, le MPP divise les données en fragments gérés en parallèle, réduisant drastiquement le temps d'exécution.
Dans l'écosystème SAS Viya 4, l'architecture MPP est incarnée par le moteur CAS (Cloud Analytic Services). Elle permet de distribuer les calculs analytiques et d'IA sur l'ensemble d'un cluster Kubernetes ou OpenShift, offrant une puissance de traitement quasi illimitée pour les Big Data..CAS Worker (MPPLe Massively Parallel Processing (MPP) est une architecture informatique où plusieurs processeurs (ou nœuds de calcul) travaillent simultanément sur différentes parties d'une même tâche complexe. Contrairement au traitement séquentiel, le MPP divise les données en fragments gérés en parallèle, réduisant drastiquement le temps d'exécution.
Dans l'écosystème SAS Viya 4, l'architecture MPP est incarnée par le moteur CAS (Cloud Analytic Services). Elle permet de distribuer les calculs analytiques et d'IA sur l'ensemble d'un cluster Kubernetes ou OpenShift, offrant une puissance de traitement quasi illimitée pour les Big Data.)workload.sas.com/class=casworkerworkload.sas.com/classcasworkerNoScheduleDédier des nœuds spécifiques pour les workers CAS en mode MPPLe Massively Parallel Processing (MPP) est une architecture informatique où plusieurs processeurs (ou nœuds de calcul) travaillent simultanément sur différentes parties d'une même tâche complexe. Contrairement au traitement séquentiel, le MPP divise les données en fragments gérés en parallèle, réduisant drastiquement le temps d'exécution.
Dans l'écosystème SAS Viya 4, l'architecture MPP est incarnée par le moteur CAS (Cloud Analytic Services). Elle permet de distribuer les calculs analytiques et d'IA sur l'ensemble d'un cluster Kubernetes ou OpenShift, offrant une puissance de traitement quasi illimitée pour les Big Data.. Export to Sheets
Ce tableau sert de guide de référence rapide pour les administrateurs, traduisant directement la stratégie de placement des charges de travail de SAS en configurations de taint concrètes. Il centralise les informations de divers documents SAS et exemples GitHub, le rendant très pratique pour la planification et l'exécution du déploiement.
Tableau : Exemples de Configurations de Tolérances pour les Pods SAS Viya
Groupe de Pods SAS ViyaClé de Taint ToléréeValeur de Taint ToléréeEffet de Taint ToléréOpérateurtolerationSecondsPods Serveur CASMoteur analytique "in-memory" de SAS Viya. Il traite les données en parallèle (MPP) sur plusieurs nœuds pour offrir une puissance de calcul massive et une exécution ultra-rapide des actions.workload.sas.com/classcasNoScheduleEqualN/APods Serveur CASMoteur analytique "in-memory" de SAS Viya. Il traite les données en parallèle (MPP) sur plusieurs nœuds pour offrir une puissance de calcul massive et une exécution ultra-rapide des actions. Controller (MPPLe Massively Parallel Processing (MPP) est une architecture informatique où plusieurs processeurs (ou nœuds de calcul) travaillent simultanément sur différentes parties d'une même tâche complexe. Contrairement au traitement séquentiel, le MPP divise les données en fragments gérés en parallèle, réduisant drastiquement le temps d'exécution.
Dans l'écosystème SAS Viya 4, l'architecture MPP est incarnée par le moteur CAS (Cloud Analytic Services). Elle permet de distribuer les calculs analytiques et d'IA sur l'ensemble d'un cluster Kubernetes ou OpenShift, offrant une puissance de traitement quasi illimitée pour les Big Data.)workload.sas.com/classcascontrollerNoScheduleEqualN/Aworkload.sas.com/classcasNoScheduleEqualN/APods Serveur CASMoteur analytique "in-memory" de SAS Viya. Il traite les données en parallèle (MPP) sur plusieurs nœuds pour offrir une puissance de calcul massive et une exécution ultra-rapide des actions. Worker (MPPLe Massively Parallel Processing (MPP) est une architecture informatique où plusieurs processeurs (ou nœuds de calcul) travaillent simultanément sur différentes parties d'une même tâche complexe. Contrairement au traitement séquentiel, le MPP divise les données en fragments gérés en parallèle, réduisant drastiquement le temps d'exécution.
Dans l'écosystème SAS Viya 4, l'architecture MPP est incarnée par le moteur CAS (Cloud Analytic Services). Elle permet de distribuer les calculs analytiques et d'IA sur l'ensemble d'un cluster Kubernetes ou OpenShift, offrant une puissance de traitement quasi illimitée pour les Big Data.)workload.sas.com/classcasworkerNoScheduleEqualN/Aworkload.sas.com/classcasNoScheduleEqualN/APods Serveur Computeworkload.sas.com/classcomputeNoScheduleEqualN/APods Services Statelessworkload.sas.com/classstatelessNoScheduleEqualN/Aworkload.sas.com/classstatefulNoScheduleEqualN/APods Services StatefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.workload.sas.com/classstatefulNoScheduleEqualN/Aworkload.sas.com/classstatelessNoScheduleEqualN/A Export to Sheets
Ce tableau complète le tableau des taints en montrant comment les pods SAS Viya sont configurés pour s'exécuter sur les nœuds correctement "taintés". Il démystifie la configuration côté pod et est essentiel pour le dépannage des problèmes de planification.
Meilleures Pratiques pour l'Implémentation et la Gestion des Taints dans SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.
L'implémentation et la gestion des taints et tolérances pour SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. nécessitent une approche méthodique, de la planification initiale à la maintenance continue. Le respect des meilleures pratiques garantit que la stratégie de placement des charges de travail est efficace, maintenable et alignée sur les objectifs de performance et de stabilité.
Planification du Placement des Charges de Travail : Considérations Pré-Déploiement
Une planification minutieuse avant le déploiement de SAS Viya est cruciale. SAS recommande fortement d'appliquer les labels et les taints à tous les nœuds, en particulier ceux destinés à CAS, avant de commencer le déploiement de la plateforme SAS Viya. Il est essentiel de développer un plan clair pour la distribution des charges de travail sur les différents pools de nœuds, en tenant compte des exigences en ressources de chaque classe de charge de travail SAS et du cycle de vie de maintenance de KubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya..
Une nuance importante pour les déploiements sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. est que, bien que la documentation SAS préconise souvent de "tainter" tous les nœuds workers selon les classes de charge, il est impératif de conserver au moins deux nœuds par défaut non "taintés" (ou "taintés" uniquement avec des taints standards OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. que les composants centraux peuvent tolérer). Ces nœuds sont nécessaires pour permettre le fonctionnement correct du contrôleur d'ingress par défaut d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site., qui a généralement un nombre de répliques configuré. Ne pas réserver ces nœuds non "taintés" peut paralyser des fonctionnalités essentielles d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.. Si tous les nœuds sont "taintés" avec des taints spécifiques à SAS, les pods essentiels d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. (comme les contrôleurs d'ingress) pourraient ne pas pouvoir être planifiés, conduisant à un clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. inaccessible ou à un routage non fonctionnel. Une implémentation pratique implique donc de créer des pools de nœuds spécifiques à SAS avec des taints, tout en s'assurant qu'un pool de nœuds distinct (souvent appelé "default" ou "infra") reste non "tainté" ou ne possède que des taints standards OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site..
Application des Taints aux Nœuds et aux MachineSets
Les taints peuvent être appliqués manuellement aux nœuds existants en utilisant la commande oc adm taint nodes <nom_du_noeud> <clé>=<valeur>:<effet> ou la commande équivalente kubectl taint nodes.... L'utilisation du drapeau --overwrite est recommandée pour mettre à jour les taints existants si nécessaire.
Cependant, pour les environnements OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site., la meilleure pratique consiste à appliquer les taints via les définitions des MachineSets. Un MachineSet est un objet OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. qui gère un ensemble de machines (nœuds). En définissant les taints au niveau du MachineSet, on s'assure que tous les nœuds créés et gérés par ce MachineSet (y compris ceux ajoutés lors d'opérations de mise à l'échelle automatique) hériteront automatiquement des taints corrects. Cela garantit la cohérence de la configuration à travers le pool de nœuds. Des exemples de structures YAML de MachineSet incluant des taints sont disponibles dans la documentation OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. et les dépôts GitHub de Red Hat pour SAS Viya. La procédure pour ajouter des taints à un MachineSet existant implique généralement de réduire le nombre de répliques du MachineSet à zéro, de modifier sa définition YAML pour inclure les taints, puis de le remettre à l'échelle au nombre de nœuds souhaité. La gestion des taints via les MachineSets OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. est supérieure aux commandes manuelles kubectl taint dans un environnement dynamique, car les MachineSets garantissent que les nouveaux nœuds créés par autoscaling ou remplacement héritent automatiquement des taints et labels corrects.
Configuration des Tolérances dans les Manifestes de Déploiement SAS Viya
Les tolérances nécessaires pour que les pods SAS Viya puissent s'exécuter sur les nœuds "taintés" correspondants sont généralement prédéfinies dans les actifs de déploiement fournis par SAS. Ces actifs incluent des fichiers de base et des overlays kustomization.yaml qui construisent le manifeste de déploiement final (site.yaml). Les administrateurs n'ont donc généralement pas besoin d'ajouter manuellement ces tolérances standards aux pods SAS. Il est toutefois crucial qu'ils soient conscients de leur existence et de leur fonctionnement, notamment pour le dépannage. Des tolérances personnalisées pourraient être nécessaires si des taints non-SAS sont appliqués aux nœuds ou pour des besoins opérationnels spécifiques. Une compréhension du fonctionnement de kustomize est utile pour appréhender comment ces tolérances sont intégrées dans le déploiement final.
Intégration avec l'API Machine et les MachineSets d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.
Comme mentionné précédemment, l'API Machine d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. et les MachineSets jouent un rôle central dans la gestion automatisée des nœuds et de leurs configurations, y compris les taints et les labels. Les définitions de MachineSet fournies par Red Hat pour les différentes classes de charges de travail SAS Viya (par exemple, cas-smpLe Symmetric Multi-Processing (SMP) est une architecture informatique où plusieurs processeurs (CPU) partagent une mémoire centrale unique et un seul système d'exploitation pour exécuter des tâches. Contrairement au mode MPP, toutes les opérations se déroulent au sein d'une seule machine ou d'un seul nœud de calcul.,
Dans l'écosystème SAS Viya 4, le mode SMP est idéal pour les jeux de données de taille petite à moyenne ou pour les phases de préparation de code. Le moteur CAS (Cloud Analytic Services) utilise alors la puissance multi-cœurs d'un nœud unique pour traiter les données avec une latence minimale.-machineset.yamlcompute-machineset.yaml) intègrent déjà les taints recommandés, ce qui simplifie grandement la configuration initiale et la maintenance.
Vérification et Ajustements Post-Déploiement
Après le déploiement, il est impératif de vérifier que les taints sont correctement appliqués et que les pods SAS Viya sont planifiés sur les pools de nœuds prévus :
- Pour vérifier les taints sur les nœuds :
oc get nodes -o=custom-columns=NAME:.metadata.name,TAINTS:.spec.taints. - Pour vérifier le placement des pods :
oc -n <namespace> get pod -o wideou une version plus cibléeoc -n <namespace> get pod -o=customcolumns=NAME:.metadata.name,NODE:.spec.nodeName | sort. - Pour supprimer un taint d'un nœud (si nécessaire pour un ajustement ou une correction) :
oc adm taint nodes <nom_du_noeud> <clé>-.
Maintien de la Cohérence à Travers le ClusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle.
L'utilisation des MachineSets est la clé pour maintenir la cohérence des taints et labels pour les nœuds au sein d'un pool. Il est également recommandé d'auditer régulièrement les configurations des taints des nœuds et des tolérances des pods, en particulier après des mises à niveau du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle., des mises à jour de SAS Viya ou des modifications significatives de la configuration du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle..
6. Impact des Taints et Tolérances sur les Opérations SAS Viya
L'implémentation stratégique des taints et tolérances a des répercussions directes et significatives sur plusieurs aspects opérationnels de SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site., notamment la performance, la haute disponibilité et la gestion globale des ressources.
Implications sur la Performance : Optimisation de l'Allocation des Ressources
Une utilisation correcte des taints pour dédier des nœuds, en particulier pour les charges de travail intensives comme CAS et Compute, est fondamentale pour la performance. En garantissant que ces composants ont un accès exclusif ou prioritaire aux ressources CPU, mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. et E/S nécessaires, on obtient des performances meilleures et plus prévisibles. Cela permet d'éviter les problèmes de "voisin bruyant", où d'autres applications pourraient interférer avec les performances de SAS Viya en consommant des ressources sur les mêmes nœuds.
À l'inverse, une mauvaise configuration des taints peut nuire aux performances. Des taints trop restrictifs pourraient conduire à une sous-utilisation de matériel spécialisé (par exemple, des nœuds GPU qui restent inactifs) ou à des goulots d'étranglement si trop peu de nœuds "taintés" sont disponibles pour une charge de travail donnée, provoquant des retards de planification.
Considérations de Haute Disponibilité : Assurer la Résilience
Les taints contribuent à la haute disponibilité (HA) en s'assurant que les composants critiques de SAS Viya sont placés sur des nœuds disposant du matériel et des configurations appropriés pour la stabilité. Lorsqu'ils sont combinés avec des configurations à plusieurs répliques pour les services stateless et une planification adéquate de la capacité des pools de nœuds, les taints aident à garantir que les charges de travail sont distribuées sur du matériel dédié et adapté.
Cependant, si les taints sont trop restrictifs et qu'un nombre insuffisant de nœuds peuvent accepter une charge de travail donnée, cela peut entraver la HA. En cas de défaillance d'un nœud ou lors d'une opération de maintenance, si les répliques ne peuvent pas être replanifiées sur d'autres nœuds appropriés (c'est-à-dire correctement "taintés" et disposant de capacité), la disponibilité du service sera compromise. Il est donc crucial que la planification de la HA tienne compte non seulement du nombre de répliques, mais aussi de la capacité et de la configuration correcte des taints/tolérances des pools de nœuds désignés pour ces pods. Les Budgets de Perturbation de Pod (Pod Disruption Budgets - PDB) doivent être utilisés conjointement avec les taints pour gérer les perturbations volontaires (comme la maintenance des nœuds) sans violer les exigences de HA pour les services SAS. La HA de SAS Viya pour les services stateless et pour CAS (avec un contrôleur de sauvegarde) repose sur la capacité de KubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya. à replanifier les pods, ce que les taints influencent directement.
Gestion des Ressources et Optimisation des Coûts
La dedication de nœuds via les taints peut conduire à une utilisation efficace du matériel spécialisé, comme les GPU, en s'assurant que seules les charges de travail autorisées les utilisent, évitant ainsi le gaspillage de ces ressources coûteuses.
Néanmoins, cela peut aussi entraîner une sous-utilisation si les pools de nœuds dédiés sont surdimensionnés par rapport à la charge de travail réelle ou si les charges de travail sont trop ségréguées, ce qui pourrait augmenter les coûts globaux du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle.. Un équilibre doit être trouvé entre l'isolation nécessaire pour la performance et la stabilité, et l'utilisation globale efficace des ressources du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle.. Une stratégie consiste à disposer d'un pool de nœuds "de secours" (failover) sans taints personnalisés, permettant aux pods de se planifier quelque part si leur pool "tainté" préféré est plein. Cependant, cela peut compromettre les garanties de performance pour les pods qui s'y exécutent. La tension inhérente entre la maximisation de l'isolation des charges de travail à l'aide de taints pour la performance/stabilité et l'optimisation de l'utilisation/coût des ressources du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. est une considération clé. Une "taintation" trop agressive sans une planification minutieuse de la capacité peut entraîner des ressources bloquées et sous-utilisées.
Considérations Avancées
Au-delà de la configuration de base, plusieurs aspects avancés méritent une attention particulière lors de l'utilisation des taints et tolérances avec SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site., notamment l'interaction avec l'autoscaling, la gestion dans des clusters partagés et la relation avec les contraintes de contexte de sécurité (SCC).
Taints, Tolérances et Autoscaling du ClusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. pour les Pools de Nœuds SAS Viya
Les pools de nœuds de calcul (Compute) de SAS Viya sont souvent de bons candidats pour l'autoscaling du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle., permettant d'ajuster dynamiquement le nombre de nœuds en fonction de la charge de travail des sessions SAS et des jobs batch.
Pour que l'autoscaling fonctionne correctement dans ce contexte :
- L'autoscaler de clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. doit être configuré pour interagir avec l'API Machine d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. et être capable de mettre à l'échelle lesMachineSetsappropriés. - Les
MachineSetsdéfinissant les pools de nœuds SAS Viya doivent inclure les taints et labels corrects dans leur template. Ainsi, lorsque l'autoscaler ajoute de nouveaux nœuds, ceux-ci sont automatiquement configurés avec les bons taints. - Les pods SAS Viya qui doivent déclencher la mise à l'échelle (par exemple, des pods de calcul en attente faute de ressources) doivent avoir les tolérances appropriées pour les taints des nœuds qui seront provisionnés.
Un défi potentiel est de s'assurer que l'autoscaler identifie correctement le besoin de faire évoluer un pool de nœuds "tainté" spécifique. Si les pods sont en attente parce qu'ils ne tolèrent pas les taints des nœuds existants (même si ces nœuds ont de la capacité), l'autoscaler pourrait ne pas réagir comme prévu. De plus, permettre à un pool de nœuds de calcul de se réduire à zéro nœud peut entraîner des délais lors de la première connexion d'un utilisateur à SAS Studio, le temps qu'un nouveau nœud soit provisionné et que les images de conteneur soient téléchargées. L'autoscaling des pools de nœuds "taintés" nécessite une intégration étroite entre l'autoscaler de clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle., l'API Machine d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. (définitions de MachineSet spécifiant les taints) et les demandes de planification de pods qui incluent les tolérances appropriées. Une inadéquation dans l'un de ces éléments peut entraîner des échecs de mise à l'échelle ou un provisionnement incorrect des nœuds.
Gestion de SAS Viya dans des Clusters OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. Partagés avec des Nœuds Non "Taintés"
Lorsque SAS Viya est déployé sur un clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. partagé avec d'autres applications, et que ce clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. contient des nœuds non "taintés" (nœuds à usage général), un défi se présente : les pods SAS Viya pourraient être planifiés sur ces nœuds généraux si leurs pools "taintés" préférés sont pleins ou mal configurés. Cela peut se produire car l'affinité de nœud par défaut de SAS Viya est souvent de type "préféré" (preferredDuringSchedulingIgnoredDuringExecution), ce qui signifie que le planificateur essaiera de respecter la préférence mais pourra placer le pod ailleurs si nécessaire.
Pour garantir un placement strict dans de tels environnements partagés :
- Il est recommandé d'utiliser une affinité de nœud "requise" (
requiredDuringSchedulingIgnoredDuringExecution) en plus des taints et tolérances. Cela force les pods SAS Viya à ne s'exécuter que sur des nœuds possédant les labels spécifiques correspondant aux pools "taintés" dédiés. - Cela peut nécessiter la personnalisation des manifestes de déploiement SAS Viya (via des patches Kustomize) pour renforcer les règles d'affinité de nœud pour les charges de travail critiques comme CAS et Compute. Dans les clusters OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. partagés, se fier uniquement à l'affinité de nœud "préférée" par défaut de SAS pour les pools "taintés" peut être insuffisant si des nœuds non "taintés" existent. L'affinité de nœud "requise" devient cruciale pour appliquer un placement strict des charges de travail pour les composants SAS critiques.
Contraintes de Contexte de Sécurité (SCCs) et leur Interaction avec les Nœuds "Taintés"
Le déploiement de SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. nécessite l'application de plusieurs Contraintes de Contexte de Sécurité (SCCs) personnalisées (par exemple, sas-cas-server-scc, sas-connect-spawner-scc) et l'utilisation de certaines SCCs prédéfinies par OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. (comme nonroot, hostmount-anyuid).
Les SCCs contrôlent les permissionsRègles d'accès définissant les actions autorisées (Lire, Écrire, Supprimer, etc.) d'un utilisateur ou groupe sur un objet ou une donnée via le service d'autorisation de SAS Viya. accordées aux pods (par exemple, les types de volumes qu'ils peuvent monter, les plages d'UID/GID qu'ils peuvent utiliser, les capacités Linux qu'ils peuvent demander). Alors que les taints et tolérances contrôlent où un pod peut être planifié, les SCCs déterminent ce qu'un pod peut faire une fois qu'il est planifié sur un nœud.
En général, les taints et les SCCs sont des mécanismes orthogonaux, mais tous deux doivent être correctement configurés pour qu'un pod SAS Viya s'exécute avec succès. Un pod peut tolérer un taint pour être planifié sur un nœud particulier, mais si son compte de service (ServiceAccount) n'est pas lié à la SCC nécessaire, le pod échouera au démarrage ou ne fonctionnera pas correctement. Par exemple, les nœuds CAS seront "taintés" pour l'isolation, et les pods CAS auront besoin de la SCC sas-cas-server-scc (ou d'une variante comme cas-server-scc-host-launch ou cas-server-scc-sssd selon les besoins d'authentification et de lancement) pour obtenir les privilèges requis pour leurs opérations.
Dépannage des Problèmes Courants Liés aux Taints dans les Déploiements SAS Viya
Même avec une planification minutieuse, des problèmes de planification liés aux taints et tolérances peuvent survenir lors du déploiement ou de l'exploitation de SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.. Savoir diagnostiquer et résoudre ces problèmes est essentiel pour maintenir un environnement stable.
Identification des Échecs de Planification dus à des Inadéquations de Taints
Le symptôme le plus courant d'un problème de taint/tolérance est un pod qui reste indéfiniment à l'état Pending.
- Pour investiguer, la commande
oc describe pod <nom_du_pod> -n <namespace>(oukubectl describe pod...) est la première étape. Les événements du pod indiqueront souvent la raison de l'échec de la planification, par exemple : "0/X nodes are available: Y node(s) had taints that the pod didn't tolerate". - Pour vérifier les taints actuellement appliqués aux nœuds :
oc get nodes -o=custom-columns=NAME:.metadata.name,TAINTS:.spec.taints. - Pour inspecter les tolérances d'un pod spécifique :
oc get pod <nom_du_pod> -n <namespace> -o yamlet examiner la sectionspec.tolerations.
Diagnostic des Pods Bloqués à l'État Pending
Si un pod est bloqué à l'état Pending à cause de taints :
- Vérifiez la correspondance exacte : Assurez-vous que la clé, la valeur (si l'opérateur est
Equal), l'effet du taint sur le nœud cible correspondent précisément à ce qui est défini dans la tolérance du pod. L'opérateur de la tolérance (EqualouExists) doit également être correct. - Labels et Affinité: Si l'affinité de nœud ou les sélecteurs de nœud sont également utilisés, vérifiez que les labels sur les nœuds cibles correspondent aux exigences d'affinité/sélection du pod, en plus de la correspondance taint/tolérance.
- Erreurs de frappe: Des erreurs typographiques dans les clés, valeurs ou effets des taints ou des tolérances sont une cause fréquente de problèmes et peuvent être difficiles à repérer.
- Tolérances manquantes pour des composants tiers: Un problème courant survient lorsque des outils personnalisés ou des agents tiers (par exemple, des agents de surveillance ou de logging) doivent s'exécuter sur des nœuds "taintés" pour SAS Viya mais n'ont pas été configurés avec les tolérances nécessaires.
Résolution des Problèmes de Capacité des Pools de Nœuds et des Taints
- Pool de nœuds plein: Si tous les nœuds d'un pool correctement "tainté" et labellisé sont saturés (c'est-à-dire qu'ils n'ont plus de ressources CPU/mémoireGemini said
Espace de stockage temporaire (RAM) utilisé par le moteur CAS pour charger et traiter les données à haute vitesse, minimisant les accès disque pour optimiser les performances de SAS Viya. disponibles pour de nouveaux pods), les pods nécessitant ce pool resteront en attente. Cela indique généralement un besoin de mettre à l'échelle le pool de nœuds (ajouter plus de nœuds auMachineSetcorrespondant). - Taints
NoExecuteet conditions de nœud: Si des taints avec l'effetNoExecutesont actifs sur des nœuds (par exemple, des taints automatiques commenode.kubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya..io/disk-pressureounode.kubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya..io/memory-pressure), les pods qui ne tolèrent pas ces conditions spécifiques peuvent être expulsés ou ne pas être planifiés. Vérifiez les conditions des nœuds (oc describe node <nom_du_noeud>) et lestolerationSecondsconfigurées sur les pods concernés. - Les discussions au sein de la communauté SAS indiquent que les problèmes de déploiement sont parfois liés à des problèmes de ressources ou de planification qui peuvent être exacerbés par des configurations de taints incorrectes.
Le dépannage des problèmes liés aux taints nécessite souvent une comparaison systématique de trois éléments : les taints définis sur les nœuds cibles (souvent via les MachineSets), les tolérances définies dans les spécifications des pods (souvent via les manifestes de déploiement SAS/kustomize), et toute règle d'affinité/sélecteur de nœud également présente sur le pod. Une inadéquation dans l'un de ces éléments peut entraîner des échecs de planification. Même si les tolérances correspondent, si les règles d'affinité de nœud sur le pod spécifient des labels que le nœud "tainté" n'a pas, le pod ne s'y planifiera toujours pas.
Des échecs "silencieux" peuvent se produire si PreferNoSchedule est utilisé et que le clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. est soumis à une charge élevée. Les pods pourraient se retrouver sur des nœuds moins optimaux, mais tolérés, sans messages d'erreur clairs, ce qui pourrait avoir un impact subtil sur les performances. Bien que moins courant dans la stratégie explicite workload.sas.com/class de SAS qui favorise NoSchedule, cela reste une possibilité à considérer.
Tableau : Dépannage des Problèmes Courants de Planification Liés aux Taints
SymptômeCause CouranteÉtapes de Diagnostic (commandes oc/kubectl)Résolution PotentiellePod en état Pending avec l'événement "didn't tolerate taints"Tolérance manquante ou incorrecte sur le pod.1. describe pod <pod> (voir les événements).<br>2. get pod <pod> -o yaml (vérifier spec.tolerations).<br>3. get node <noeud_cible> -o yaml (vérifier spec.taints).Ajouter/corriger la tolérance dans la définition du pod (souvent via Kustomize pour SAS Viya) et redéployer.Pod en état Pending avec l'événement "didn't tolerate taints"Erreur de frappe dans la clé/valeur/effet du taint ou de la tolérance.Idem ci-dessus, vérifier attentivement les chaînes de caractères.Corriger l'erreur de frappe sur le nœud (via MachineSet ou oc adm taint) ou dans la tolérance du pod.Pod en état Pending avec l'événement "didn't match node selector" ou "node(s) didn't match pod affinity rules"Le nœud "tainté" et toléré ne possède pas les labels requis par l'affinité/sélecteur du pod.1. describe pod <pod> (voir les événements).<br>2. get pod <pod> -o yaml (vérifier spec.affinity / spec.nodeSelector).<br>3. get node <noeud_cible> --show-labels.Ajouter le label manquant au nœud (ou via MachineSet) OU ajuster/supprimer la règle d'affinité/sélection sur le pod.Pods SAS Viya planifiés sur des nœuds "par défaut" non "taintés" au lieu des pools dédiésPool de nœuds "tainté" plein OU affinité "préférée" utilisée dans un clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. partagé.1. get pod -n <ns> -o wide (vérifier les nœuds).<br>2. Vérifier la capacité des nœuds dans le pool cible (describe node).<br>3. get pod <pod> -o yaml (vérifier si l'affinité est preferred... ou required...).Augmenter la taille du pool de nœuds cible (via MachineSet) OU modifier l'affinité en "requise" (required...) pour les pods critiques.Pod expulsé (Evicted) avec raison liée à un taint NoExecuteUn taint NoExecute a été ajouté au nœud (manuellement ou par condition) et le pod ne le tolère pas (ou tolerationSeconds a expiré).1. describe pod <pod> (voir les événements).<br>2. describe node <noeud> (vérifier les conditions et les taints NoExecute).<br>3. get pod <pod> -o yaml (vérifier les tolérances pour les taints NoExecute et tolerationSeconds).Ajouter la tolérance appropriée au pod OU résoudre la condition du nœud (si possible) OU déplacer manuellement la charge de travail si le taint est permanent. Ce tableau fournit une approche structurée pour diagnostiquer et résoudre les problèmes courants rencontrés par les administrateurs. Il traduit les problèmes observés en chemins de diagnostic et de résolution exploitables, répondant directement aux besoins pratiques du public cible.
Conclusion et Recommandations Clés
L'utilisation efficace des taints et tolérances est fondamentale pour le succès du déploiement et de l'exploitation de SAS Viya 4SAS Viya 4 est une plateforme d'IA, de data management et d'analytics de pointe, nativement conçue pour le Cloud (Cloud-Native). Contrairement aux versions précédentes, elle repose sur une architecture de microservices orchestrée par Kubernetes.
Elle permet de gérer l'intégralité du cycle de vie de la donnée — de l'ingestion à la mise en production des modèles (ModelOps) — en offrant une élasticité totale, une intégration transparente avec l'open-source (Python, R) et une interface unifiée pour les data scientists et les décideurs métiers. sur Red Hat OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.. Ces mécanismes KubernetesKubernetes est l'orchestrateur open source gérant le déploiement, la mise à l'échelle et l'exécution conteneurisée des microservices de l'architecture cloud-native de SAS Viya., lorsqu'ils sont appliqués de manière stratégique, permettent d'aligner l'infrastructure sous-jacente sur les exigences architecturales spécifiques de SAS Viya, favorisant ainsi l'isolation des charges de travail, l'optimisation des ressources et l'amélioration des performances globales.
La complexité de SAS Viya, avec ses différentes classes de charges de travail aux besoins variés (CAS, Compute, Stateless, StatefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé.), rend indispensable une approche de placement contrôlé. Les taints, en repoussant les pods indésirables, et les tolérances, en permettant aux pods ciblés d'accéder aux nœuds dédiés, constituent les outils principaux pour mettre en œuvre la stratégie de pools de nœuds recommandée par SAS.
Les recommandations clés suivantes émergent de l'analyse :
- Utiliser des Pools de Nœuds Dédiés (MachineSets) : La création de pools de nœuds distincts, gérés via des
MachineSetsOpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site., pour les différentes classes de charges de travail SAS Viya (en particulier CAS, Compute, StatefulUne app stateful sauvegarde ses données sur un volume persistant. Si le pod redémarre, son état est conservé., Stateless) est la pratique fondamentale. - Appliquer les Taints Recommandés par SAS via MachineSets : Utiliser le schéma de taints
workload.sas.com/class=<class_name>:<effect>(principalementNoSchedule) et les intégrer dans les définitions desMachineSetspour garantir la cohérence et l'automatisation. - Vérifier les Tolérances des Pods SAS Viya : Bien que généralement prédéfinies par SAS, s'assurer que les pods SAS Viya possèdent les tolérances correspondant aux taints des nœuds sur lesquels ils doivent s'exécuter.
- Combiner avec l'Affinité de Nœud : Pour un contrôle précis et une dedication garantie, combiner les taints/tolérances avec des règles d'affinité de nœud (souvent "requise" dans les environnements partagés).
- Gérer les Nœuds Non "Taintés" d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. : Réserver impérativement au moins deux nœuds par défaut non "taintés" (ou avec des taints standards tolérés par les composants OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.) pour les services essentiels du clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. comme le contrôleur d'ingress. - Intégrer avec l'Autoscaling : Configurer l'autoscaler de clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. pour qu'il fonctionne correctement avec les
MachineSets"taintés", en s'assurant que les pods en attente ont les bonnes tolérances pour déclencher la mise à l'échelle du pool approprié. - Auditer et Vérifier Régulièrement : Contrôler périodiquement la configuration des taints, des tolérances et le placement effectif des pods pour maintenir la cohérence et détecter les dérives.
En conclusion, les taints et tolérances sont des outils puissants mais qui nécessitent une compréhension approfondie et une planification rigoureuse dans le contexte de SAS Viya sur OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site.. Un équilibre doit être trouvé entre l'isolation stricte pour la performance et la flexibilité nécessaire pour une utilisation efficace des ressources et la haute disponibilité. La gestion via les MachineSets d'OpenShiftOpenShift est la plateforme Kubernetes d'entreprise de Red Hat conçue pour orchestrer, sécuriser et gérer le cycle de vie des applications conteneurisées.
Pour SAS Viya 4, OpenShift agit comme la fondation "Cloud Native" indispensable : il automatise le déploiement des microservices SAS, garantit la haute disponibilité des calculs analytiques et permet une portabilité totale entre le cloud public (Azure, AWS, GCP) et les infrastructures sur site. et une vérification continue sont essentielles pour garantir que la stratégie de placement des charges de travail reste alignée sur les besoins évolutifs de la plateforme SAS Viya dans un environnement cloud-natif dynamique.