
La meilleure façon de comprendre CAS est de comprendre la terminologie et les concepts utilisés.
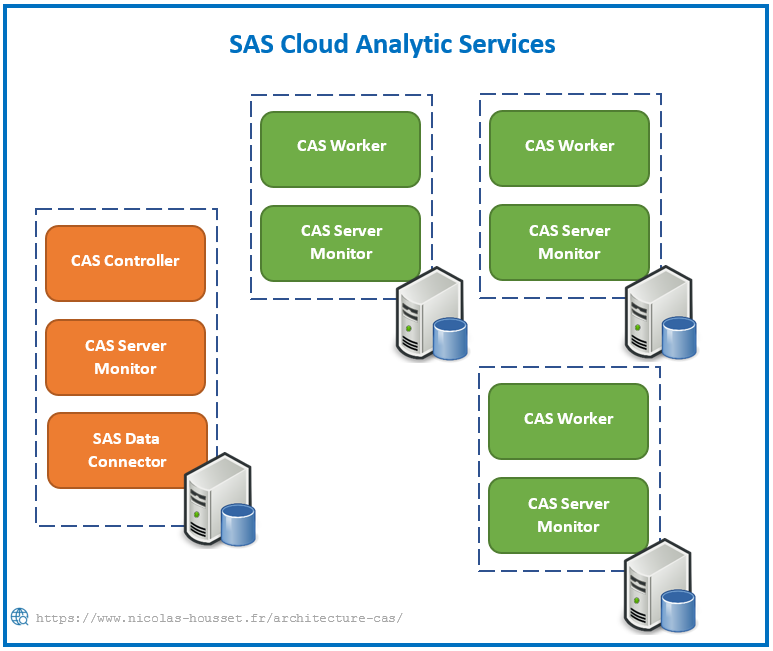
 En mode MPP, CAS permet le traitement parallèle sur les multiples workers :
En mode MPP, CAS permet le traitement parallèle sur les multiples workers :
 Ces deux modes offrent à un administrateur beaucoup de liberté pour configurer le système CAS de manière avantageuse pour leur utilisateurs.
Un utilisateur peut souhaiter travailler avec CAS en mode SMP, sur un serveur simple, pour travailler et développer sur une application avant d'être éventuellement sur un cluster MPP.
Ces deux modes offrent à un administrateur beaucoup de liberté pour configurer le système CAS de manière avantageuse pour leur utilisateurs.
Un utilisateur peut souhaiter travailler avec CAS en mode SMP, sur un serveur simple, pour travailler et développer sur une application avant d'être éventuellement sur un cluster MPP.
Le CAS controller
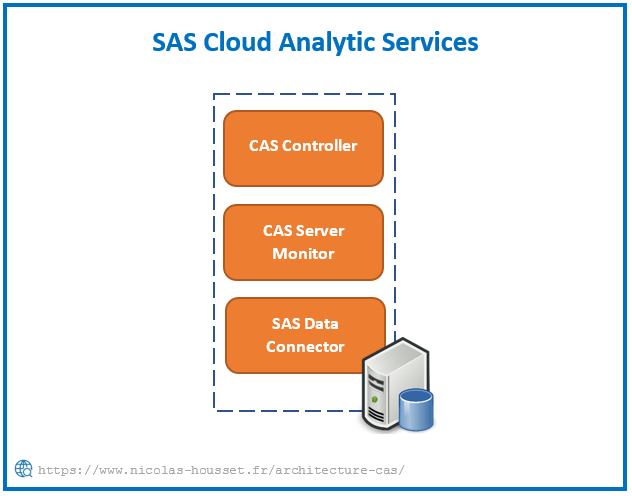
Le système CAS comprend de 1 à plusieurs node. Un node est désigné "contrôleur". Le contrôleur exécute un processus en tant que server controller et un processus pour chaque server worker. Le contrôleur est le référentiel pour l'état global de CAS. Le client se connecte au contrôleur de serveur. Une fois authentifié, le CAS controller crée un processus de session sur le contrôleur et sur chaque worker à inclure dans cette session. La connexion du client est ensuite transférée vers le contrôleur de session. À ce stade, le client peut commencer à soumettre des travaux à CAS.Les CAS workers
L'objectifs des CAS workers est d’exécuter la même demande que les autres workers et du CAS controller, et de traiter les données locales. Cela permet à l’utilisateur ou à l’administrateur d’étaler les données sur le cluster pour permettre le traitement parallèle local des données qui seront ensuite rassemblées pour produire un résultat. CAS peut être déployé dans l’un des deux modes suivants:- SMP: Symmetric Multi-Processing
- MPP: Massive Parallel Processing
CAS en mode SMP
CAS en mode MPP
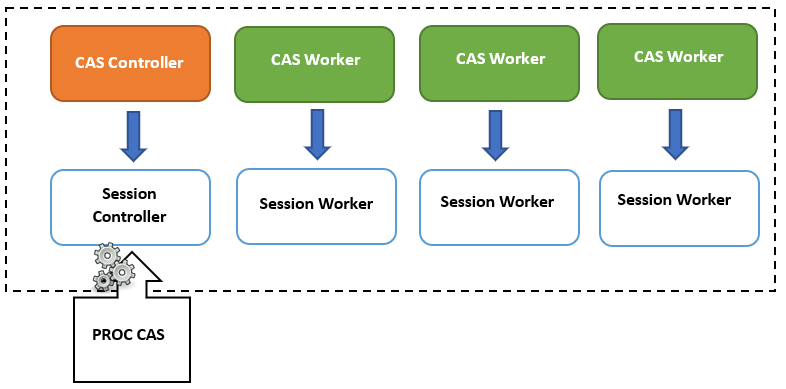
Les sessions
CAS utilise des sessions pour suivre les utilisateurs et offre une interface de sécurité complète pour protéger les données au niveau fichier, comme au niveau colonne. Cette connexion à CAS a pour objectif de pouvoir exécuter des requêtes du serveur. Aussi, un utilisateur doit créer une session avant de pouvoir soumettre une requête. Une fois l’utilisateur authentifié, le contrôleur de serveur crée un processus session controller pour utilisateur et un processus session worker pour chaque CAS worker.